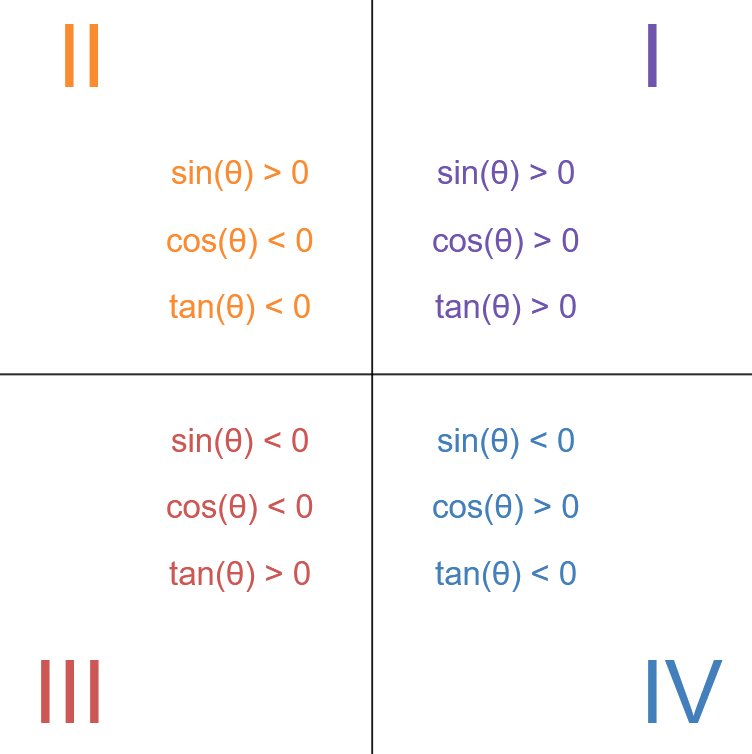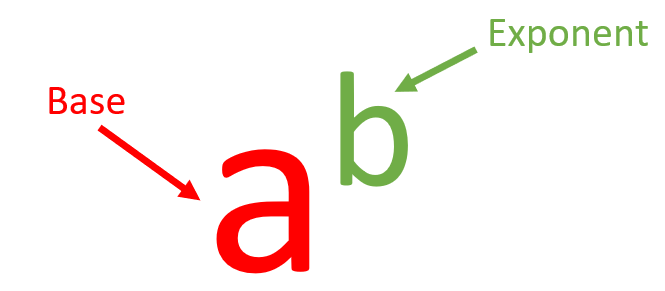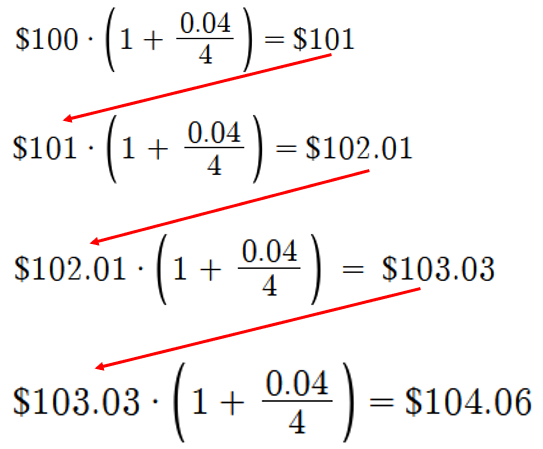In order to seek truth, it is necessary once in the course of our life, to doubt, as far as possible, of all things.
— René Descartes
1.1 Motivating Calculus
In this life, you should always be asking yourself the following questions: Why am I doing this? Should I be doing something else? Why should I read a textbook on Calculus? Why will I need it?
In the author’s opinion, there are two primary reasons why one should learn Calculus. First, the universe is expressed in mathematics generally and Calculus in particular. This connection between mathematics and the natural world will be explored in the last chapter of this text, Chapter 11. Through this text, you will become more connected to the universe in which you live and will have the power to predict the way it behaves. Second, mathematics is an enormously creative and artistic subject brimming with possibility. The world of mathematics is at least as large as all realizable forms in the universe. The space for exploration is great, and using very basic tools one can achieve experiences that would be impossible without mathematics and computation.
1.1.1 Understanding the Universe
Refraction
Some readers may be familiar with the idea of refraction. Refraction refers to light’s tendency to bend upon encountering a boundary between two transparent media: air and water, water and glass, glass and diamond, and so on. Why does light bend at the intersection between media? Using a bit of physical insight coupled with Calculus, we will arrive at an answer to this question. Consider the diagram below:
We imagine light travelling from point \(A\) in medium 1 (say air) to point \(B\) in medium 2 (say glass). These different media have different indices of refraction, which will affect the speed of light in these media. For some values of \(n_1\) and \(n_2\) (the indices of refraction of medium 1 and 2, respectively), can you find the path which minimizes the time it takes for light to go from \(A\) to \(B\)? It turns out that this is a model we can use to explain why light bends. Suppose I were to change the positions of \(A\) and \(B\). How would we determine the path of shortest time in that case? What if I change the media? Suppose, for instance, I change glass to diamond and have the light pass from the air into the diamond. What will happen then? As before, light will follow the path of shortest time, but how can we find it?
Problems involving maxima and minima are the meat and potatoes of Calculus. They are often called optimization problems. We will find that we can derive physical laws using concepts from Calculus like the calculation of maxima and minima.
Period and Pendulums
Let’s consider another example. Suppose you are given the length and mass of a pendulum and you are on another planet. Can you determine what the period of the pendulum will be? Play with the illustration below.
What causes the period of the pendulum, or the time required for one full swing, to increase? Which factors cause it to decrease? Why? These are also questions you will be able to answer yourself after reading Chapter 11. The equations may seem intimidating now, but don’t worry. We will learn each concept slowly, and by the end you will see that you are capable of not only understanding, but also deriving these equations yourself.
1.1.2 Art and Mathematics
Unfortunately, math is often practiced and taught by individuals who are effectively automatons. Occasionally, mathematics is blessed with individuals of immense creativity, but often its most ardent proponents are little more than calculators. This has lead the general public to believe that mathematics is a dull, lifeless subject for crunching numbers. Consider the illustration below.
True mathematicians are poets and artists. They are mavericks who attempt to break humanity free from established habits of thinking. As you read this book, you may feel at times that you are bogged down in details and separated from the bigger picture and the art. Don’t be discouraged, it happens to all of us. If you work at it, you will have a rigorous set of tools with which to express your thoughts and your creativity.
We will start slow. Make sure you understand every detail thoroughly–mathematics is a subject which builds upon itself. By the end of this book, the mathematical and natural worlds will be open for you to explore. Enough grandiose promises… Read this book and have fun.
1.2 Function Basics
1.2.1 Function Definition
Much of what will be described in this book relates to functions. A function is a mathematical machine that is defined over some set of numbers, accepts some number of inputs (for most of this book, there will only be one input), and returns some output. In particular, a function is only allowed to return one output for each input. The following is an example of a function. You can move the arrows anywhere and the illustration will remain a function. That is because each input is associated with one output.
If you wished, every arrow can point to the same output and the object would remain a function.
The following is an example of an object which is not a function since multiple arrows are extending from the same input (in this particular case, there are two outputs for the input 1). The only way it could be made a function is if the arrows extending from the input are forced to map onto the same output.
We almost never express functions this way. Instead, we will plot functions on the Cartesian Coordinate Plane. To identify a function on the coordinate Plane, we use the Vertical Line Test. In the vertical line test, we imagine a vertical line scrolling across the plane from left to right and ensure that the vertical line intersects the graph at most once for each value of \(x\). The following functions pass the Vertical Line Test:
We know these are functions because the black dotted line passes through only one point for each of the colored plots. You can click on each function to bold it to confirm that the vertical line only ever passes through a single point.
The following are not functions because they fail the Vertical Line Test:
Notice that the yellow function fails at only a single point. A mathematical object fails the Vertical Line Test if a vertical line goes through two points for any\(x\). It should be noted that just because a mathematical object fails the Vertical Line Test (and thus fails to be a function) does not imply that it is not useful. Indeed, we will be using non-functions repeatedly throughout this book. However, the vast majority of the Calculus results we develop will involve functions.
Exercise 1.1 Use the following Desmos Plot to produce a mathematical object which fails the Vertical Line Test.
1.2.2 Polynomial Functions
A function is called a polynomial if the equation describing it is given by
where \(n\) is a nonnegative integer called the degree of the polynomial and \(c_n, \dots, c_0\) are real numbers called the coefficients of the polynomial. If a polynomial is of degree n, then it must be that \(c_n\) is not equal to zero. All polynomials are defined over the entire real line. The illustration below depicts some polynomial functions.
Degree 0 Polynomials
Degree 0 polynomials are simply constant functions. For all values of \(x\), they return the same value for \(y\). An illustration of degree 0 polynomials is provided below:
Degree 0 polynomials are parallel to the \(x\)-axis. Therefore, most degree 0 polynomials have no roots, except for the trivial case when the constant function is equal to zero.
Degree 1 Polynomials (Lines)
Degree 1 polynomials are lines with a nonzero slope. In slope-intercept form, the equation is given by
\[f(x) = ax + b,\]
where \(a \neq 0\). An illustration of degree 1 polynomials is provided below:
The \(a\) is called the slope of the line, while \(b\) is called the \(y\)-intercept. The steeper the line, the greater the slope. If the line is downward facing, the slope is negative. The \(y\)-intercept is the value at which the line hits the \(y\)-axis.
If we want to find the \(x\)-intercept of a line, we simply set the function \(f(x)\) equal to zero:
Quadratic polynomials are degree 2 polynomials. They take the form
\[f(x) = ax^2 + bx + c,\]
where \(a \neq 0\). Play with the illustration below to get a sense of what quadratic polynomials, most often called parabolas, look like.
The values of \(x\) where the function \(f(x)\) is zero are called the roots of the function. For quadratic polynomials, the roots are given by the quadratic formula:
The parabola contacts the \(x\)-axis twice (as you can confirm). We say there are two real roots to the equation.
Case 2\(b^2 - 4ac = 0\)
The parabola contacts the \(x\)-axis exactly once. In this case, there is one real root and one imaginary root to the equation. Imaginary numbers will be discussed in 1.8.
Case 3\(b^2 - 4ac < 0\)
The parabola never makes contact with the \(x\)-axis. In this case, there are two imaginary roots to the equation.
Note that in all three cases, a polynomial of degree 2 has 2 solutions to the equation \(ax^2 + bx + c = 0\).
Degree 3 Polynomials (Cubics)
Polynomials of degree 3 are called cubic polynomials. They take the following form:
\[f(x) = a_3 x^3 + a_2 x^2 + a_1 x + a_0,\]
where \(a_3 \neq 0\). Degree three polynomials look like the following:
As was true for quadratic polynomials, cubic polynomials always have three roots. There is always at least one real root for cubic polynomials. There can also be two or three real roots, depending on the function. In general, a polynomial of degree n has \(n\) roots which can be either real or imaginary.
Polynomials and Physics
Polynomials are ubiquitous in all mathematical sciences. A notable, simple example is the trajectories of launched objects. Suppose we have two baseballs: one is dropped from height \(h\) while the other is thrown sideways from height \(h\). This is illustrated below:
Let \(t\) be the length of time that the thrown ball has fallen. Let \(v_{0x}\) be the speed at which the ball is initially thrown. The distance \(x\) that the ball has traveled along the \(x\)-axis is given by
\[x(t) = v_{0x}t\]
This is the equation of a line. Meanwhile, the vertical distance the ball has fallen, \(y\), is given by
\[y(t) = y_0 + v_{0y}t - \frac{1}{2}gt^2,\]
which is the equation of a parabola. In Chapter 11 (11.1.2), we will derive both of these formulas using Calculus.
1.2.3 Rational Functions
Rational functions are the ratio of two polynomial functions.
1.2.4 Even and Odd Functions
1.2.4.1 Illustration of Even Functions
Usually in this book, we will focus first on describing the intuition behind a concept before formalizing that concept with mathematical notation.
An even function is one which is symmetric about the y-axis. Below are the functions \(y = x^2\) and \(y = \cos(x)\). Center each of the function at the origin, and move the \(a\) slider. Notice that the horizontal bar connecting the two points remains horizontal, no matter the value of the slider \(a\). In general, if \((x, y)\) is a point on a plot, then another point on the plot is \((-x, y)\).
Parabola:
Cosine:
Exercise 1.2 Use the following Desmos Plot to construct your own even function. Confirm that \((x, y) = (-x, y)\) for all \(x\).
1.2.4.2 Illustration of Odd Functions
An odd function is one which is anti-symmetric about the y-axis. This means that if one point on a plot is \((x, y)\), then another point on the plot is \((-x, -y)\). That is, in the figures below, if one of the vertical segments is up at \(x = a\), the other is down at \(x = -a\) by the same amount.
Below are the functions \(y = x^3\) and \(y = \sin(x)\). Both of these functions are odd.
Cubic:
Sine:
1.2.4.3 Definition of Even and Odd Functions
Now that we have nice pictures of even and odd functions, we want to describe these pictures using mathematical notation. How should we do this? The descriptions of even and odd functions preceding each picture gives a clue as to how we might rigorously define each type of function.
Even Function Definition
Recall that for an even function, the value of \(y = f(x)\) is the same as the value of \(y\) at \(-x\). Therefore, our definition is as follows:
Definition 1.1 (Definition of Even Functions) A function is called even if the following is true for all \(x\) in the domain of the function \(f\):
For an odd function, the value of \(y = f(x)\) is the opposite of the value of \(y\) at \(-x\). That is, we must add a negative sign when going from \(-x\) to \(x\). Therefore, our definition is the following:
Definition 1.2 (Definition of Odd Functions) A function is called odd if the following is true for all \(x\) in the domain of the function \(f\):
Example 1.1 (Even and Odd Functions) For each of the following functions, indicate whether the function is even or odd:
\(f(x) = x\sin x\)
\(f(x) = \cos(x^2)\)
\(f(x) = x + \sin x\)
\(f(x) = x + \cos x\)
For the first function, we note that \(f(x)\) is really the product of two functions: \(x\) and \(\sin x\). We already saw in the diagram above that \(\sin x\) is odd, so \(\sin(-x) = -\sin(x)\). This is probably obvious, but it is also the case that \(f(x) = x\) is odd since \(f(-x) = -x\) and \(-f(x) = -x\), so \(f(-x) = -f(x)\). Therefore, we have:
Therefore, because \(f(x) = f(-x)\), the function \(f(x) = x\sin x\) is even.
Now we consider the function \(f(x) = \cos(x^2)\). We know from the diagrams above that \(f(x) = x^2\) and \(f(x) = \cos x\) are both even. In particular, \(f(-x) = (-x)^2 = (-1)^2\cdot x^2 = x^2 = f(x)\). Therefore, we have:
Therefore, because \(f(-x) = -f(x)\), \(f(x) = x + \sin x\) is an odd function.
Finally, consider the function \(f(x) = x + \cos x\). We know that \(x\) is odd while \(\cos x\) is even. Therefore, we have:
\[f(-x) = (-x) + \cos(-x) = -x + \cos(x)\]
Note that \(f(x) = x + \cos x \neq -x + \cos x\) and \(-f(x) = -x - \cos x \neq -x + \cos x\). Therefore, \(f(x) = x + \cos x\) is neither even nor odd.
Note that most functions are neither even nor odd. However, the concept of even and odd functions will be important for some of the arguments we make regarding derivatives in Chapter 3.
1.2.4.4 Applying Even/Odd Definition
Your turn! Answer the following questions and make sure you understand the answer.
1.3 Circle Theorems and Formulas
In this section, we prove a number of theorems, formulas, and identities which will be useful throughout this text.
1.3.1 Radius and Tangent are Perpendicular
A result that will appear repeatedly when working with trigonometric functions is the fact that the tangent of a circle and its radius are perpendicular, meaning they meet at right angles.
Theorem 1.1 Suppose a tangent line contacts a circle at some point \(P\). Then the radius of the circle is perpendicular to the tangent line at point \(P\).
The meaning of this is illustrated below.
Moreover, you can see a proof of this by clicking the “Show Proof” button. Such buttons will arise frequently throughout this book. It isn’t necessary to understand the proof, but the reader must be familiar with the results. It should be noted that understanding the proofs will provide a deeper understanding of math and will help you understand the source of those results you must know.
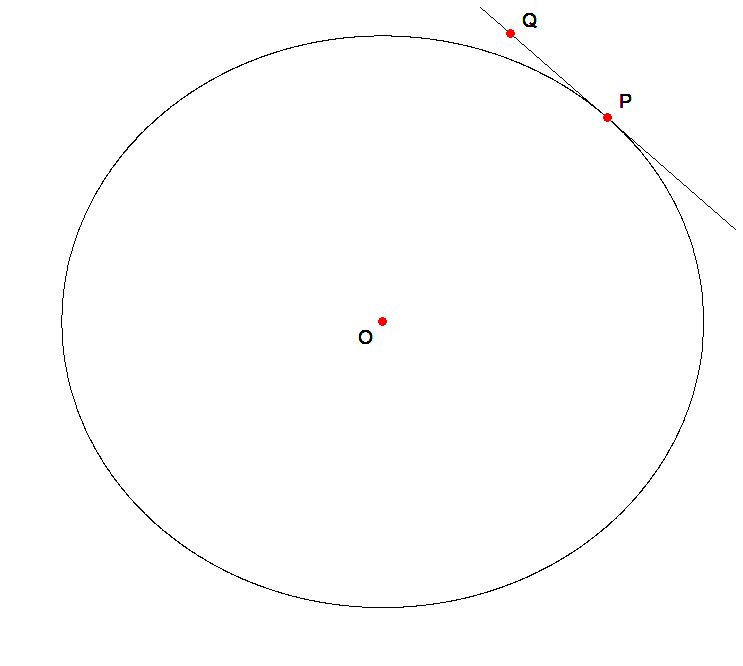
Begin by drawing a circle with center \(O\). Draw a tangent to the circle, and let the point at which the tangent contacts the circle be point \(P\). Note that any other point \(Q\) on the tangent to the circle lies outside the points defining the circle. See the illustration below.
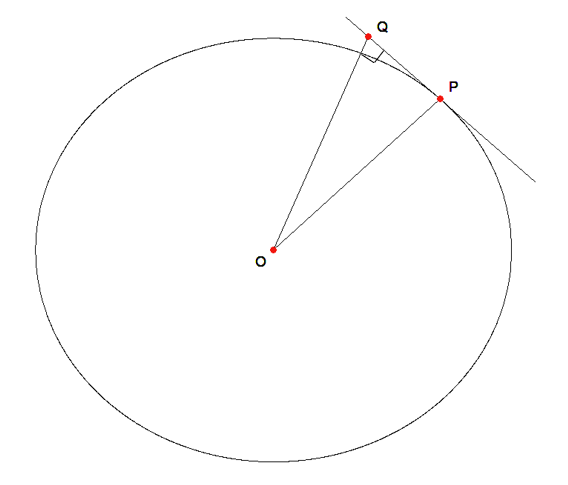
Now, if we extend segments from the center \(O\) of the circle to the tangent line, one such segment must be perpendicular to the tangent line (since we could draw a line of any slope emanating from the origin). Suppose that this perpendicular line does not occur at point \(P\), but at some other point \(Q\). Draw segments \(OQ\) and \(OP\) to form triangle \(\Delta OQP\). Note that this is a right triangle; in particular, \(\angle OQP\) is a right angle. See the illustration below.
If \(\angle OQP\) is a right angle, then segment \(OP\) must be the hypotenuse of the right triangle \(\Delta OQP\). Therefore, we conclude that the length of segment \(OP\) is greater than the length of segment \(OQ\); but this is impossible, since \(P\) lies on the circle and \(Q\) lies outside the circle. Therefore, it could not have been true that the point defining the right angle could have occurred for any point except for point \(P\). Hence, the radius and the tangent are perpendicular at point \(P\).
1.3.2 Arc Length of a Circle and Radians
The reader is likely already familiar with the circumference of the circle, \(C = \pi d = 2\pi r\), where \(d\) is the diameter of the circle and \(r\) is the radius. Circumference is the length going around the circle exactly once. Later in this text, we will need to be able to compute the arc length of the circle for any angle \(\theta\). How can we determine the arc length of a circle? For that matter, how does one actually prove the circumference formula above? We first provide a little activity the reader can do to empirically determine the circumference. Then, we will provide a sketch of a proper proof that the circumference\(C = \pi d\).
Example 1.2 (Circle Plot Activity) Below, we have provided a number of circles in a .png with their centers included. The objective is to determine the circumference of these circles.
Download and print the picture circlePlotActivity.png. Draw a point somewhere on the circle and a diameter through the center of the circle. Measure this diameter with a ruler.
Then, obtain some twine/string/fishing line and place it along the circumference of the circle. Use some tape to keep the twine/string/fishing line in place. Wrap the string around the circle once and cut the string where the ends meet. Then, measure the length of the string. Divide the length of the string by the diameter for all three circles. Do you get the same answer each time? What answer(s) do you get?
The foregoing activity is a simple but crude way at arriving at the circumference of a circle. It is a method the ancient Egyptians and Babylonians might have used to obtain an approximation for the value of \(\pi\). How might we begin to derive a rigorous means of arriving at the formula for the circumference of a circle? Below is an idea which we could use to arrive at an approximation of \(\pi\) (and the circumference):
This method was referred to in ancient Greece as “the method of exhaustion”. For this particular illustration, it involves inscribing a regular polygon (a polygon whose sides are the same length) within a circle of radius 1. A similar method was used by Archimedes (c. 287 - 212 BC) to obtain an approximation of \(\pi\). Note that in his time, he did not have computers, trigonometric functions, or even decimal numbers! Indeed, the system of positioning digits with respect to a decimal was invented some time between the 1st and 4th centuries in India.
Despite his complete lack of technology (and mathematics!) he was able to use this diagram to arrive at an approximation of \(\pi\) which was accurate to the hundredths place.
In the Appendix of this book, we have provided a step-by-step calculation using this method to obtain an approximation for \(\pi\) in the spirit of Archimedes. Here, we will comment only on the illustration above. First, notice that as the slider is moved right, the number of segments increases; furthermore, those segments approach the boundary defining the circle (we encourage the reader to zoom in toward the boundary of the circle to watch how closely the circumference is approximated by the polygon). Second, notice that as the number of sides is increased, the perimeter of the polygon (the ugly looking formula beneath the slider) approaches \(2\pi\), which is the circumference of the circle.
This ingenious method is the essence of Calculus. We have some quantity we wish to compute (in this case, the circumference). To determine the circumference, we approximate the the curved boundary of the circle with an increasing number of shorter segments. As the number of segments increases, they do a better job approximating the circumference. Note that for any given number of segments, the perimeter of the polygon will never equal the real circumference, but they become ever closer to the circumference as we let \(n\) become larger and larger. To capture this idea, we say that in the limit as n approaches infinity, the perimeter of the polygon equals the circumference of the circle. This idea of a limiting process will appear ad nauseum over the course of this book: it is this idea which forms the basis of the entire subject.
We can perform exactly the same procedure for a circle of any size to show that the circumference of a circle is given by the formula \(C = 2\pi r\), where \(r\) is the circle’s radius.
The foregoing illustration demonstrates that a circle of radius 1 has a circumference of \(2\pi\). Another is provided below. In this case, we have a circle rolling along the x-axis. The green point only returns to its starting position once the circle has rolled a distance of \(2\pi\):
Recall that we set out to determine the arc length for an arc corresponding to any angle \(\theta\). Before we do so, we need a unit to measure the angle \(\theta\) in which we’re interested. The most natural unit of an angle is the radian. It is the most natural unit since it depends on the only quantity which defines a circle: its radius.
Definition 1.3 (Radian) 1 radian is the angle created by an arc whose length is equal to the radius of the circle containing that arc.
To see what this really means, consider the illustration below:
As the slider is moved right, the arc on the circle and the radius of the circle reach their endpoints at the same time: they are the same length. That is, 1 radian is the angle swept by an arc whose length is the same as the radius of the circle. The reader is (hopefully) already familiar with angles being measured in degrees. \(1 \hspace{1.5mm}\text{radian} \approx 57.3^{\circ}\).
Why is this unit so special? Well, it allows us to relate the arc length, angle, and radius of a circle in one definition. We know that the angle measure of one full turn of a circle is \(360^{\circ}\). What is the measure of one full turn of a circle for the radian unit? The illustration below helps us arrive at the answer:
In the figure above, all of the colors except for yellow sweep out 1 radian. Therefore, we have six radians plus a little extra represented by the yellow arc. The length of that yellow arc is \(0.2831853...\), so it sweeps out that angle in radians, too. Adding these, we find the total angle measure in radians is \(6.2831853 = 2\pi\)! Why did that happen? First, recall that the circumference of a circle is \(C = 2\pi r\). Also remember that a radian is, by definition, the angle made by an arc equal in length to the radius of the circle. Therefore, the radian measure of one full turn is how many radii are necessary to overlap the circumference of the circle. Because \(C = 2\pi r\), we need \(2\pi\) radii to equal the circumference, so one full turn about the circle is \(2\pi \hspace{1.5 mm} \text{radians}\).
Now that we have the radian angle measure for one full turn of a circle, we can find any angle of interest on the circle. For instance, turning \(180^{\circ}\) is a half turn on the circle. Because the radian measure of one full turn is \(2\pi\), half the circle will be \(\pi \hspace{1.5mm}\text{radians}\). Below is a comparison of angles that show up often in practice, expressed in the units of radians and degrees:
Example 1.3 (Degrees to Radians) Convert \(75^{\circ}\) to radians.
From the arguments and illustrations provided above, we know that \(\pi \hspace{1.5 mm} \text{rad} = 180^{\circ}\). Therefore, we can convert \(75^{\circ}\) by multiplying by the fraction \(\frac{\pi}{180^{\circ}}\):
\[75\cdot\frac{\pi}{180} = \frac{5\pi}{12}\]
Therefore, \(75^{\circ}\) is the same as \(\frac{5\pi}{12}\) radians.
Example 1.4 (Radians to Degrees) Convert \(\frac{4\pi}{5}\) radians to degrees.
As was true in the previous example, \(\pi \hspace{1.5 mm} \text{rad} = 180^{\circ}\). To convert from radians to degrees, we multiply by \(\frac{180^{\circ}}{\pi}\):
\[\frac{4\pi}{5}\cdot\frac{180}{\pi} = 144^{\circ}\]
Therefore, \(\frac{4\pi}{5}\) radians is the same as \(144^{\circ}\).
1.3.3 Area of a Sector
Imagine a circle as a pizza. The reader is certainly familiar with the formula for the area of a circle \(A = \pi r^2\). Suppose we wanted the area of a slice of that pie. Such an area is called a sector of the circle. How do we compute the area of a sector?
Example 1.5 (Area of Sector) Suppose we wanted to compute the area of the sector (the purple region) when \(\theta = \frac{\pi}{4}\):
How should we do so? Recall that the total angle around a circle is \(360^{\circ} = 2\pi \hspace{2mm} \text{radians}\). The sector sweeps out an angle \(45^{\circ} = \frac{\pi}{4}\hspace{1mm}\text{radians}\). Counting the slices made in the circle, we see that the slice is \(\frac{45^{\circ}}{360^{\circ}} = \frac{\pi/4}{2\pi} = \frac{1}{8}\) of the total circle’s area. Therefore, the area is \(A = \left(\frac{1}{8}\right)\cdot(\pi r^2) = \left(\frac{1}{8}\right)\cdot (9\pi) \approx 3.5343 \hspace{1mm}\text{units}^2\)
Now suppose you are given a sector of angle \(\theta\) and radius \(r\). How would you compute the area of that pizza slice? Following the last example, we first find the fraction of the circle occupied by the sector. We do this by dividing the angle \(\theta\) made by the pizza slice by the total angle of the circle, (\(2\pi\)): \(\frac{\theta}{2\pi}\). As the reader already knows, the area of the circle is \(\pi r^2\). Therefore, the area of an arbitrary sector is given by \(\frac{\theta}{2\pi}\cdot\pi r^2 = \frac{1}{2}r^2\theta\).
This equation will also be used repeatedly in this text, so it will be numbered:
\[\begin{equation}
A = \frac{1}{2}r^2\theta
\tag{1.4}
\end{equation}\]
1.4 Trigonometric Functions
In this section we will understand the basics of trigonometry. It turns out that triangles and circles are very closely related. The functions we will be analyzing are illustrated below:
1.4.1 Basic Trigonometry
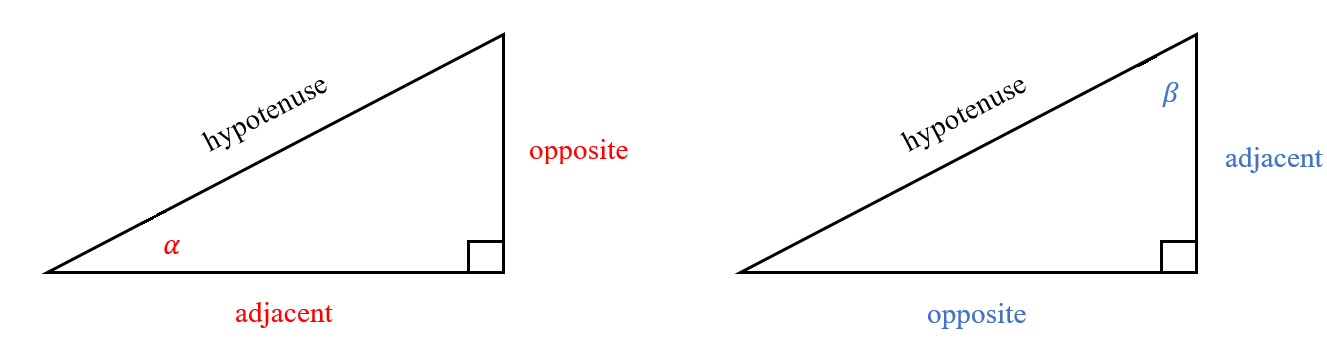
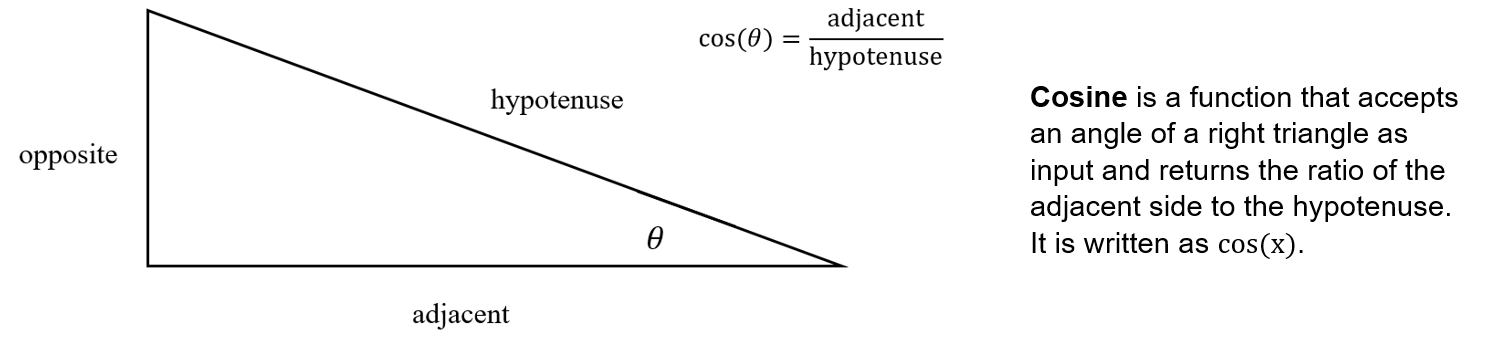
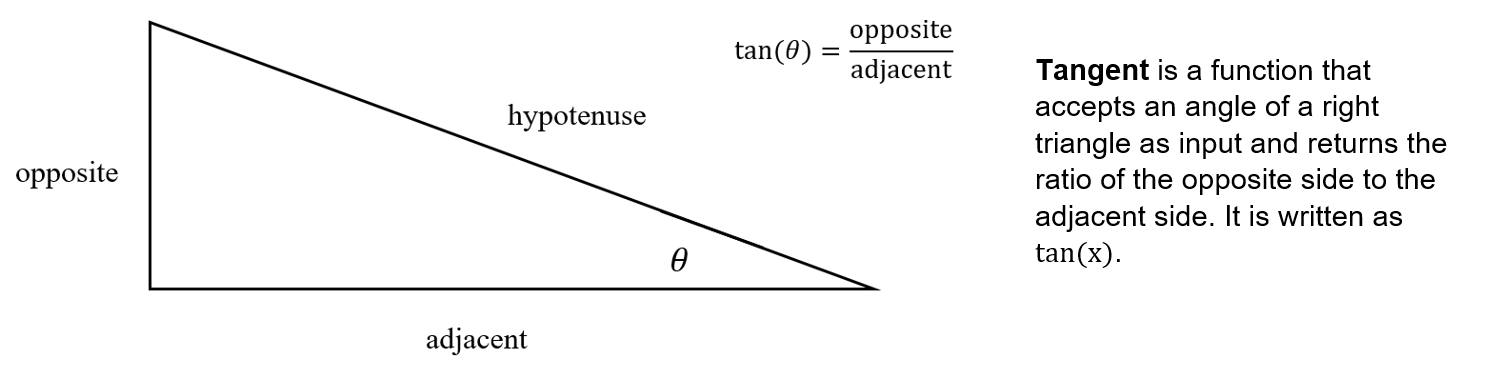
In physics and math, we are very often interested in the properties of right triangles. In particular, we would like to be able to draw conclusions about the measures of angles from a right triangle’s sides, and vice versa. We label a right triangle relative to the angle of interest:
In the figure above, notice that the label for hypotenuse is fixed–it is always the side opposite the right angle. Furthermore, it is longest side of the right triangle. The other sides of the triangles are called legs.
The label for adjacent is relative to the angle. For angle \(\alpha\), adjacent is at the bottom of the triangle, beside \(\alpha\). For angle \(\beta\), adjacent is on the right-hand side of the triangle, beside \(\beta\).
The label for opposite is always the leg furthest from the angle of interest. For angle \(\alpha\), the opposite leg is the one furthest from \(\alpha\) on the right hand side of the triangle. Similarly, for angle \(\beta\), the opposite leg is the one furthest from \(\beta\) on the bottom of the triangle.
Notice that the opposite side for angle \(\alpha\) is equal to the adjacent side for angle \(\beta\). This will be imporant in proving the Law of Sines, 1.2.
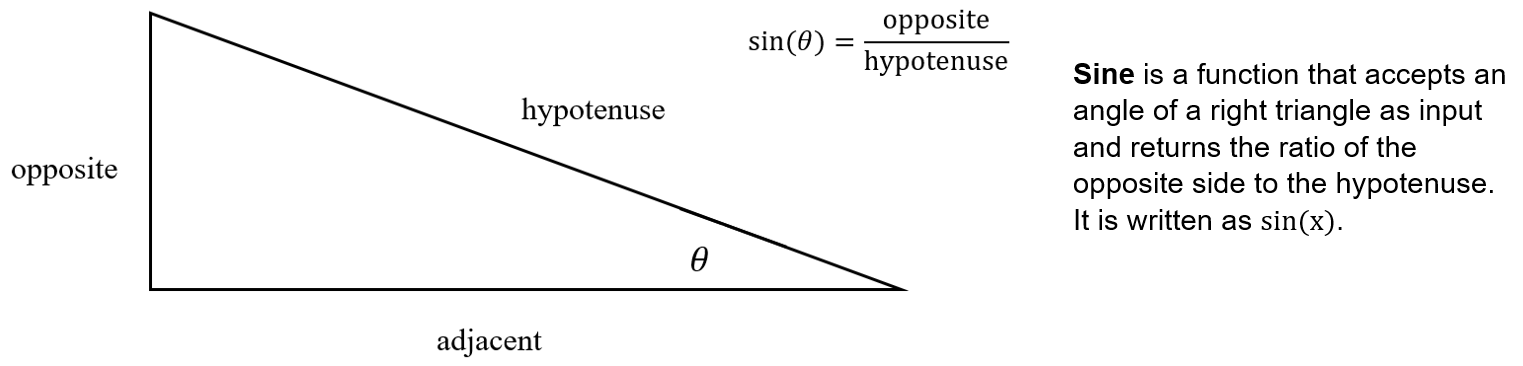
Our objective is to connect the angles of a triangle with its sides. There are several functions that allow us to make this connection:
An important point to notice is that the sine, cosine, and tangent functions are themselves connected. Since \(\sin(\theta) = \frac{\text{opposite}}{\text{hypotenuse}}\) and \(\cos(\theta) = \frac{\text{adjacent}}{\text{hypotenuse}}\), we can take their ratio:
\[\frac{\sin(\theta)}{\cos(\theta)} = \frac{\frac{\text{opposite}}{\text{hypotenuse}}}{\frac{\text{adjacent}}{\text{hypotenuse}}} = \frac{\text{opposite}}{\text{hypotenuse}}\cdot\frac{\text{hypotenuse}}{\text{adjacent}} = \frac{\text{opposite}}{\text{adjacent}} = \tan(\theta)\]
This identity is so important that we will number it:
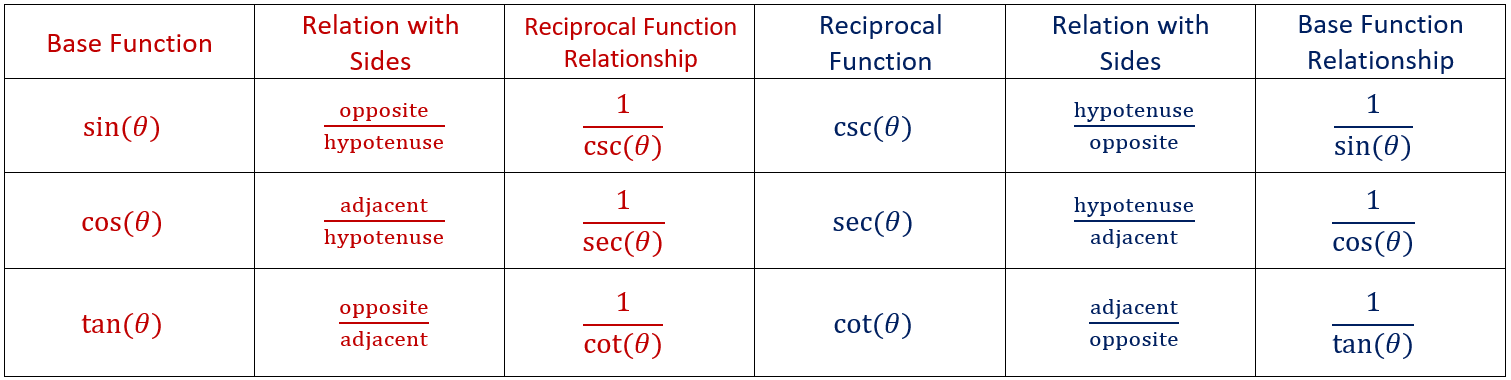
There are other trigonometric functions worth mentioning. They behave exactly as sine (\(\sin(\theta)\)), cosine (\(\cos(\theta)\)), and tangent (\(\tan(\theta)\)) do. In fact, the three “new” functions, cosecant (\(\csc(\theta)\)), secant (\(\sec(\theta)\)), and cotangent (\(\cot(\theta)\)), are simply the reciprocals of sine, cosine, and tangent. They are rarely useful in their own right, but they will show up frequently when integrating in Chapter 6. Therefore, we document the relationship between the trigonometric functions and their reciprocals. We will link to this table repeatedly in this text.
Figure 1.1: Relationship between Trigonometric functions sine, cosine, tangent, cosecant, secant, and cotangent.
1.4.2 Trigonometric Functions and The Unit Circle
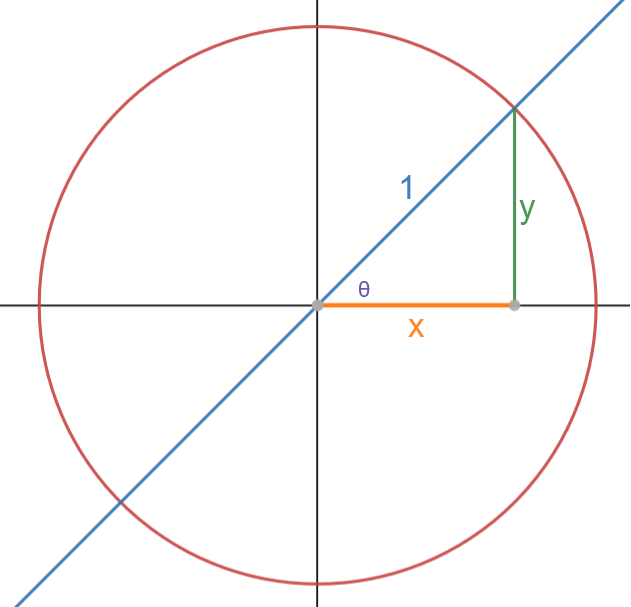
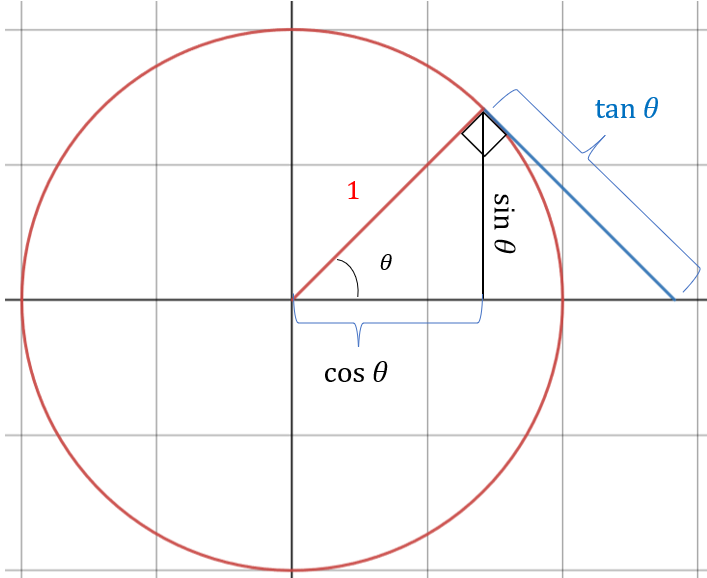
There exists an important relationship between trigonometric functions and circles. In this section, we will restrict our focus to circles with a radius of 1 unit. Such a circle is called a unit circle. We construct a right triangle with the radius as its hypotenuse. The figure looks like this:
We need to determine the value of y and x. How do we do this? Recall that by definition, \(\sin(\theta) = \frac{\text{opposite}}{\text{hypotenuse}} = \hspace{1 mm}\frac{y}{1}\). Therefore, \(y = \sin(\theta)\). On the other hand, by definition, \(\cos(\theta) = \frac{\text{adjacent}}{\text{hypotenuse}} = \hspace{1mm}\frac{x}{1}\). Therefore, \(x = \cos(\theta)\). Note that because we have a right triangle, we have \(x^2 + y^2 = 1\), so \(\cos^2(\theta) + \sin^2(\theta) = 1\). This formula will appear repeatedly in this text, so we give it a number:
As long as we are considering a unit circle, \(x=\cos(\theta)\) and \(y = \sin(\theta)\) for any angle \(\theta\) around the circle. This is illustrated in the figure below:
A critical detail is the sign of sine and cosine for different parts of the plane; in particular, for what angles are sine, cosine, and tangent positive or negative. The reader can play with the illustration above to get a sense of the signs of the sine, cosine, and tangent functions. They are summarized here for the reader’s convenience:
1.4.3 Sine, Cosine, and Tangent Plots
Sine, Cosine, and Tangent can be plotted along the x-axis, too. These representations are particularly when describing wave behavior. The wiggles in the graphs of sine and cosine will also be very valuable when we discuss Fourier Analysis in Chapter BLANK.
There is a visually pleasing connection between the unit circle and the plots for \(\sin(\theta)\), \(\cos(\theta)\), and \(\tan(\theta)\). These are provided below.
1.4.3.1 Sine
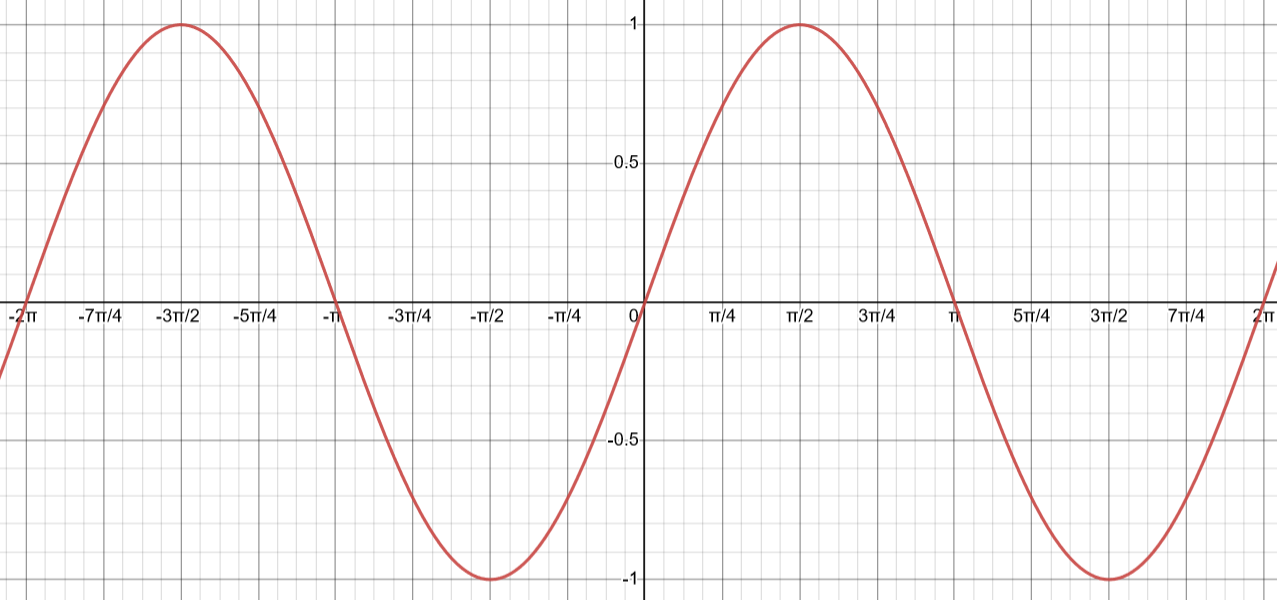
For sine, the x-coordinate is the angle of the radius about the circle, while the distance of the point on the circle from the x-axis is the y-coordinate:
If we allow the angle to rotate in the opposite direction (which corresponds to a negative angle), then we would find that the sine function appears like this:
1.4.3.2 Cosine
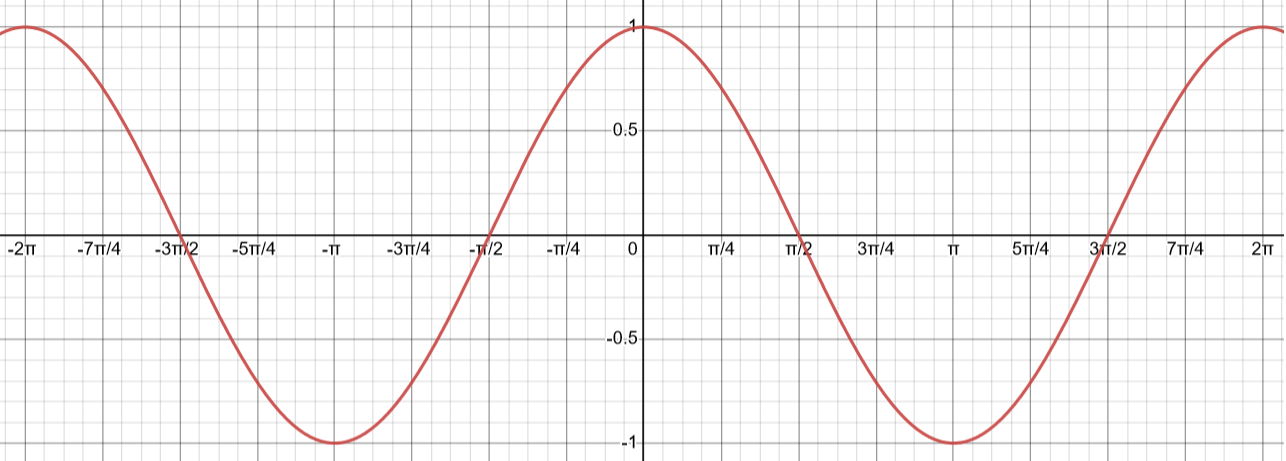
For cosine, we once again allow the radius to rotate around the unit circle and record the value of cosine for each angle. This results in a wavelike function very similar in appearance to sine. Note, however, that \(\cos(0) = 1\), so the hill of cosine appears at \(x=0\):
If we allow the radius to rotate for negative angles and rotate the whole function so that it aligns with the x-axis, the cosine function will result. The function appears below:
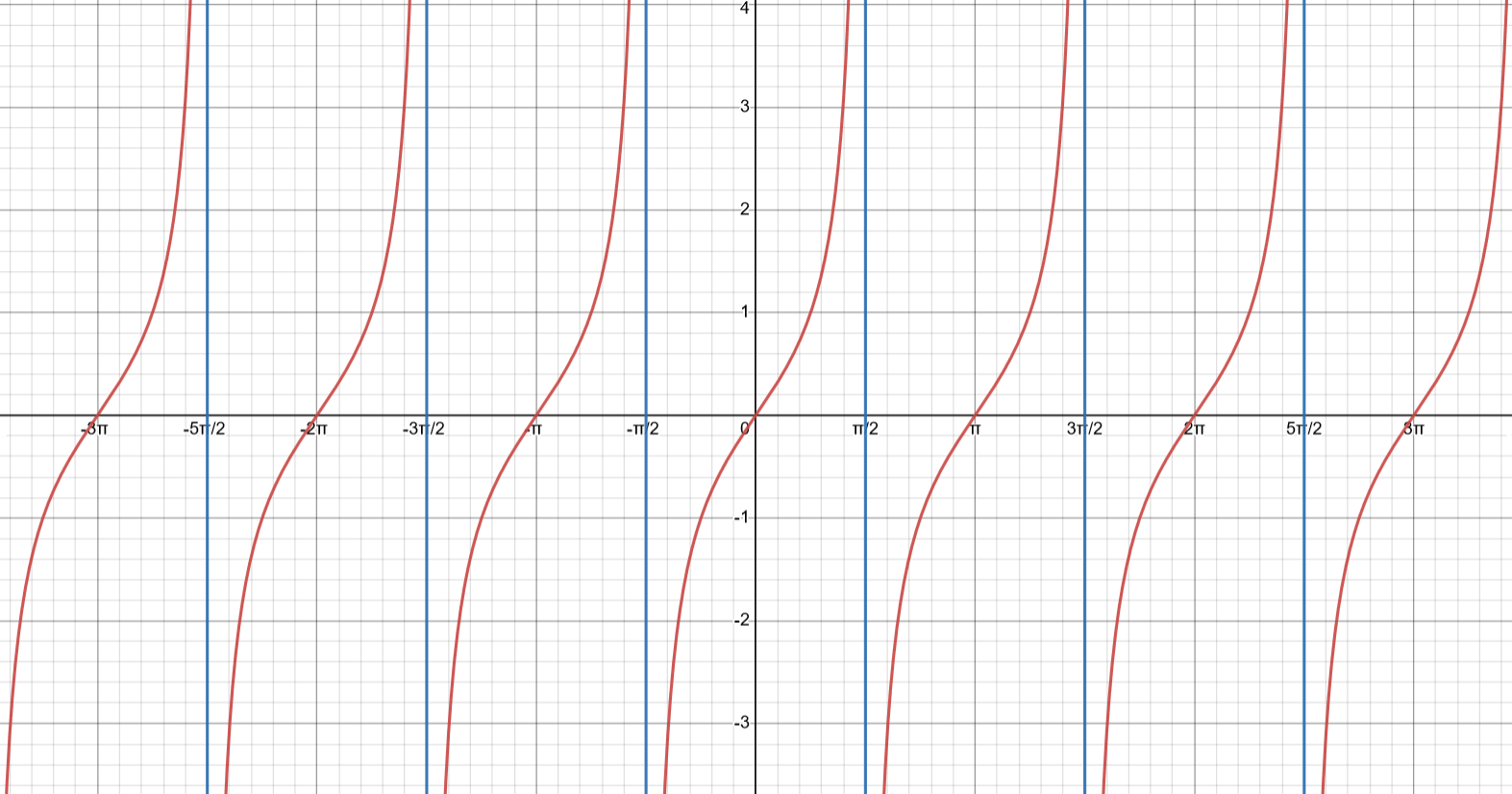
1.4.3.3 Tangent
Producing the plot for the tangent function is significantly more involved than it is for sine and cosine; in fact, most authors completely avoid describing why the tangent function appears as it does.
To understand the origin of the tangent plot, first consider the following diagram. It shows that the tangent to the circle actually determines the value of tangent (hence the name):
To understand why this is so, recall that we proved 1.1, from which we concluded that the radius of a circle and its tangent are perpendicular. Therefore, if we were to draw a tangent of the red circle and extend it until it contacted the x-axis, we would produce a right triangle. The hypotenuse must be the black segment between the red and blue segments, since the hypotenuse is always opposite the right angle. Therefore, given angle \(\theta\) and recalling that \(\tan(\theta) = \frac{\text{opposite}}{\text{adjacent}}\), we can calculate the length of the opposite side. We know the adjacent side is the radius of the unit circle, which is one. Therefore, we have \(\tan(\theta) = \frac{\text{opposite}}{\text{adjacent}} = \frac{\text{opposite}}{1} \Rightarrow \text{opposite} = \tan(\theta)\).
Recall the formula (1.5). Notice that this formula implies that if \(\sin(\theta) > 0 \hspace{1mm}\text{and} \cos(\theta) > 0\) or if \(\sin(\theta) < 0 \hspace{1mm}\text{and} \cos(\theta) < 0\), then \(\tan(\theta) > 0\).
On the other hand, if \(\sin(\theta)\) and \(\cos(\theta)\) are oppositely signed, then \(\tan(\theta) < 0\). The red below corresponds to \(\tan(\theta) > 0\), while the orange corresponds to \(\tan(\theta) < 0\).
Therefore, the value of tangent is given by the length of the tangent line of the circle when extended from the circle to the x-axis. The red and orange colors determine when the function is positive or negative:
Therefore, if we extend this function to negative angles, the following plot would result. This is the plot corresponding to the tangent function:
1.4.4 Sum and Difference Identities
There are four formulas we will need when we compute the derivatives of functions two chapters from now, though these are useful identities in their own right. They look intimidating at first glance, but don’t worry: you will understand what they mean and their origin. They are the following:
We will provide proofs of the first two identities. We leave it as an exercise to the reader to prove the others by following the techniques for proving the first two.
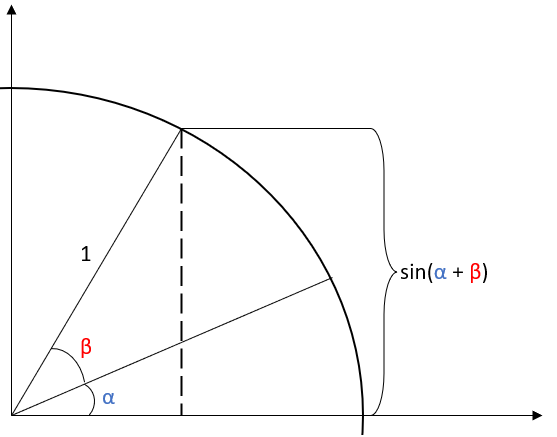
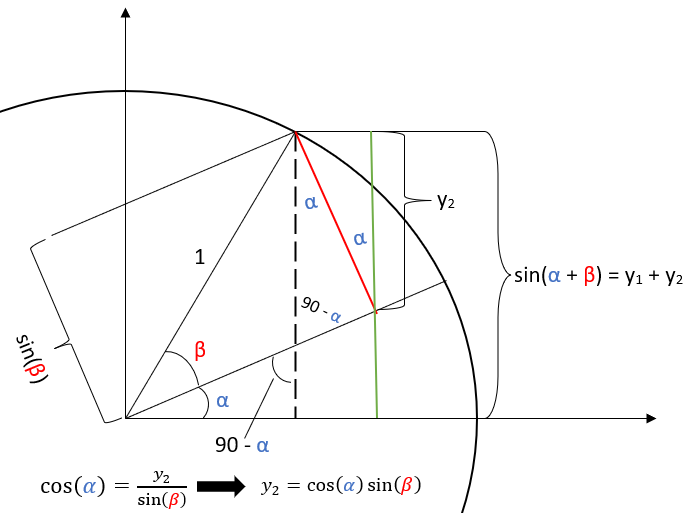
To begin, we draw a circle of radius 1, with two radii at angles \(\alpha\) and \(\alpha + \beta,\) as illustrated below:
Note that the quantity we seek is sin(\(\alpha\) + \(\beta\)), also illustrated in the figure above.
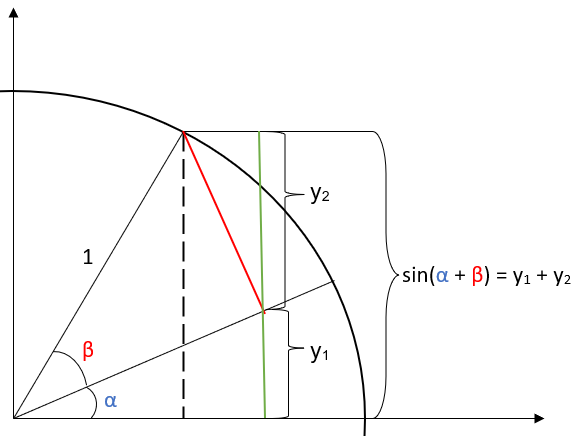
Next, we draw a perpendicular (the red segment) from the upper radius to the lower. We also draw a green segment through the point where the red segment meets the lower radius up to the point where the upper radius meets the circle. The figure below illustrates this:
Note that if we find the values of \(y_1\) and \(y_2\), then we simply add them together to obtain \(\sin(\alpha + \beta)\). We will find \(y_1\) first, then we will determine \(y_2\).
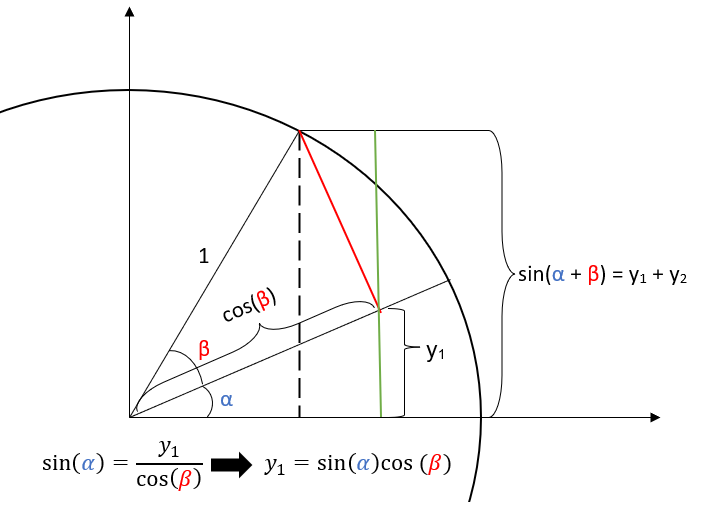
The figure below shows how to compute \(y_1\). The right triangle with angle \(\alpha\) has opposite leg \(y_1\) and hypotenuse \(\cos\)(\(\beta\)). Therefore, since \(\sin\)(\(\alpha\)) \(= \frac{\text{opposite}}{\text{hypotenuse}}\), we have \(\sin\)(\(\alpha\))\(=\frac{y_1}{\cos(\beta)}\), as illustrated below:
Wonderful! To complete the proof, we now must find \(y_2\). We will erase some of the details from the previous picture and focus only on those pertinent for finding \(y_2\). First, note that the right triangle with angle \(\beta\) has the red segment as its opposite side. Since the hypotenuse is the radius with length 1, the length of the red segment is simply \(\sin\)(\(\beta\)). Finally, using the diagram, you can see that the angle made between the red segment and the green segment is \(\alpha\). Therefore, because \(y_2\) is the adjacent to angle \(\alpha\) and \(\sin\)(\(\beta\)) is the hypotenuse, we have \(\cos\)(\(\alpha\))\(=\frac{\text{adjacent}}{\text{hypotenuse}}\)\(=\frac{y_2}{\sin(\beta)}\)
Therefore, since \(\sin(\alpha + \beta) = y_1 + y_2\), \(\sin(\alpha + \beta) = \sin(\alpha)\cos(\beta) + \cos(\alpha)\sin(\beta)\), as was to be shown.
Next, we will prove the second identity. This proof is much simpler than the first.
From the previous proof, we know that \(\sin(\alpha + \beta) = \sin(\alpha)\cos(\beta) + \sin(\beta)\cos(\alpha)\). Suppose we let \(\beta \rightarrow -\beta\). Then we have:
We have a visualization of formulas 2.7 and 2.8 above. Notice that as the slider is dragged to the left from \(0\) (meaning we are subtracting more from \(x\)), the sine function \(\sin(x + a)\) shifts to the right. On the other hand, as the slider is dragged right from \(0\) (meaning we are adding more to \(x\)), the function shifts to the left. This is in accordance with our previous observations regarding horizontal function shifts.
Furthermore, there are some values of the slider \(a\) which deserve special attention. Notice that for \(a = \frac{\pi}{2} \approx 1.571\), the two functions overlap. This is a visual demonstration for formula (1.11). That is, if we add \(\frac{\pi}{2}\) to \(x\) and apply the sine function, it overlaps perfectly with the cosine function. Also notice that when \(a = -\frac{\pi}{2} \approx -1.571\), the functions are exactly opposite. This is a visual demonstration of (1.12). That is, when sine is shifted by \(a = -\frac{\pi}{2}\), it aligns with \(-\cos(x)\).
We should note that these are only visual demonstrations of these facts, not proofs. In fact, we can use formulas (1.7) - (1.10) to prove formulas 2.7 - 2.10. To prove formula (2.7), simply use formula (2.3) and plug in \(\alpha = x\) and \(\beta = \frac{\pi}{2}\). We obtain the following:
Recalling that \(\sin\left( \frac{\pi}{2}\right) = 1\) and \(\cos(\frac{\pi}{2}) = 0\), we find \(\sin(x + \frac{\pi}{2}) = \cos(x)\), which is (1.11).
1.4.5 More Trigonometric Identities
We have already uncovered some interesting formulas relating sine, cosine, and tangent functions. Such relationships are extravagantly referred to as trigonometric identities. These identities are incredibly valuable in physics, math, and engineering. This will become especially apparent when we begin integrating. We will first provide some examples of proving trigonometric identities, which will be followed by exercises for the reader to practice.
Show that \(\sin(2\theta) = 2\sin(\theta)\cos(\theta)\).
Using formula (1.7), demonstrating this identity is trivial. We simply let \(\alpha = \theta\) and \(\beta = \theta\). Upon substituting these variables, we have:
\[ \sin(\alpha + \beta) = \cos(\alpha)\sin(\beta) + \sin(\alpha)\cos(\beta)\]\[ \sin(\theta + \theta) = \cos(\theta)\sin(\theta) + \sin(\theta)\cos(\theta)\]\[\sin(2\theta) = 2\sin(\theta)\cos(\theta)\]
As was to be shown.
Show that \(\cos^2(\theta) = \frac{1 + \cos(2\theta)}{2}\).
Recall (1.6). From this formula, we know that \(\sin^2(\theta) + \cos^2(\theta) = 1\). We want to isolate \(\cos^2(\theta)\), so we subtract \(\cos^2(\theta)\):
\[\sin^2(\theta) = 1 - \cos^2(\theta)\]
Furthermore, using formula (1.9), we can let \(\alpha = \theta\) and \(\beta = \theta\), so that
We will complete one more example, then the reader is encouraged to attempt the exercises which follow.
Show that \(\frac{\sin^2(\theta)}{\cos(\theta) - 1} = -1 - \cos(\theta)\)
Recall that \(\sin^2(\theta) + \cos^2(\theta) = 1\) so \(\sin^2(\theta) = 1 - \cos^2(\theta)\). Note that \(1 - \cos^2(\theta) = \left(1 - \cos(\theta)\right)\left(1 + \cos(\theta)\right)\) since \(1 - \cos^2(\theta)\) is a perfect square. Therefore, we have:
Using sine, cosine, and tangent, we have been able to connect the angles of a right triangle with the lengths of its sides. Now suppose we are given the sides of a right triangle, and we wish to determine the angles of that triangle. This can be accomplished using the inverse functions of \(\sin(x)\), \(\cos(x)\), and \(\tan(x)\). These functions are called \(\arcsin(x)\) (pronounced ‘ark-sine’), \(\arccos(x)\) (pronounced ‘ark-cos’), and \(\arctan(x)\) (pronounced ‘ark-tan’).
1.4.7 Law of Sines
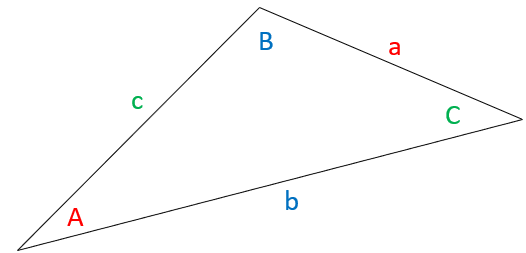
All of our discussion so far involved right triangles and their relationship with circles. Using sine, cosine, and tangent, we were able to relate the length of the sides of a right triangle with its angles. Can the same be done for a general triangle? The answer is yes using the Law of Sines. Suppose we have the following triangle:
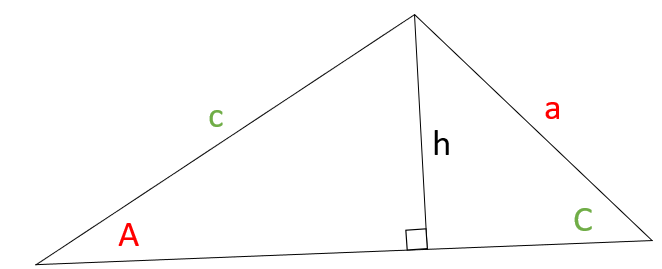
Proof (Law of Sines). First, draw an altitude \(h\) from angle \({\color{blue}\angle }{\color{blue} B}\) to the side of length \({\color{blue} b}\):
We now have two right triangles. Therefore, we can apply the formulas for sine for angles \({\color{red} A}\) and \({\color{green} C}\). The altitude \(h\) is the opposite side for both angles. Therefore, we have:
\[\sin({\color{red} A}) = \frac{h}{{\color{green} c}} \Rightarrow h = {\color{green} c}\sin({\color{red} A})\]
and
\[ {\color{green} c}\sin({\color{red} A}) = {\color{red} a}\sin({\color{green} C}) \]
Dividing \({\color{red} a}\) and \({\color{green} c}\) from both sides, we have:
This same procedure can be performed by dropping an altitude from angle \({\color{red} A}\) or \({\color{green} C}\). Doing so would allow us to show that \(\frac{{\sin({\color{blue} B})}}{{\color{blue} b}}\) is equal to the others. This concludes the proof.
Example 1.6 (Law of Sines Example 1) This will be the first example of the Law of Sines!
Example 1.7 (Law of Sines Example 2) This will be the second exmaple of the Law of Sines!
1.5 Introduction to Vectors
1.5.1 Definition
The last few chapters of this book will be devoted to vector calculus, or calculus for functions that accept more than one input. But what is a vector?
There are several definitions and many more notations describing vectors. While these definitions and notations are equivalent, the one we invoke depends on the problem we are considering. Often (particularly in physics), it is described as a mathematical object with magnitude and direction. It is equally often described as a group of numbers describing the difference between a vector’s tip and its tail.
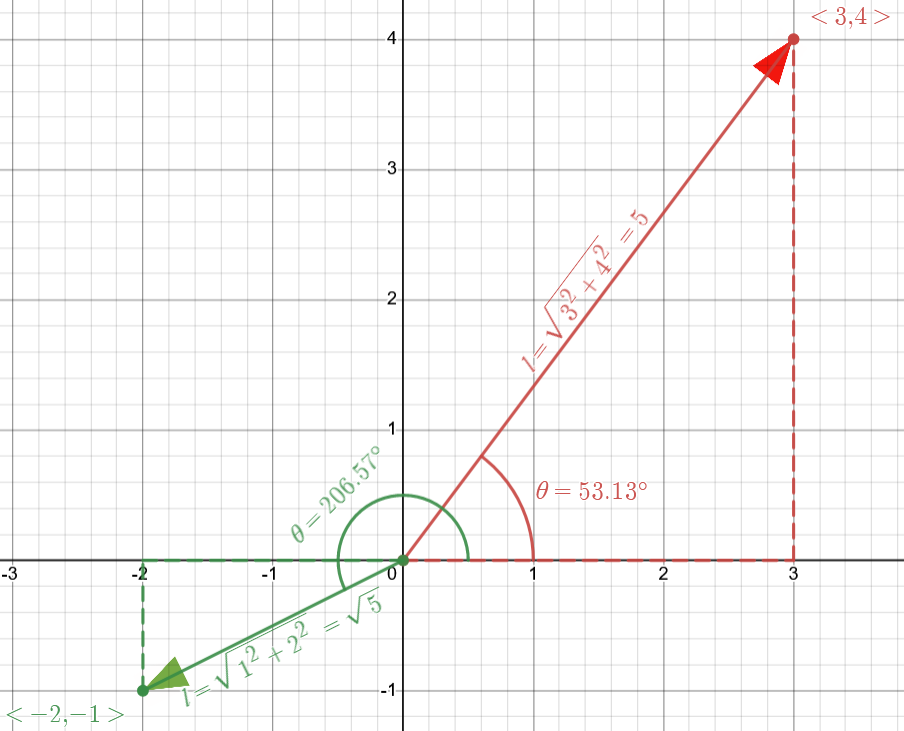
Below, two vectors are depicted with these definitions:
The red vector is \(3\) units right and \(4\) units up relative to the origin. This is denoted by \(\langle 3, 4\rangle\). It is also often written as \(\begin{pmatrix} 3 \\ 4 \end{pmatrix}\). Alternatively, it is the vector of length \(5\) rotated an angle \(53.13^{\circ}\) counterclockwise from the horizontal. Similarly, the green vector is \(2\) units left and \(1\) unit down from the origin, so it is denoted by \(\langle-2, -1\rangle\) or \(\begin{pmatrix} -2 \\ -1 \end{pmatrix}\). It is also the vector of length \(\sqrt{5}\) rotated an angle \(206.57^{\circ}\) counterclockwise from the horizontal.
The arrowhead or endpoint of a vector is called its tip. The point from which the vector emanates is its tail. In this case, the tail of both vectors is the origin.
There is one final notation that will prove useful when discussing vector calculus later in the text. This is the unit vector notation. A unit vector is any vector with length one. In the diagram below, \(\hat{i} = \langle 1, 0\rangle \hspace{1mm} \text{or} \begin{pmatrix} 1 \\ 0\end{pmatrix}\) and \(\hat{j} = \langle 0, 1\rangle \hspace{1mm} \text{or} \begin{pmatrix} 0 \\ 1\end{pmatrix}\) are unit vectors along the x- and y-axes, respectively. Any vector in the plane can be expressed as a combination of these unit vectors. For instance, the red vector above \(\vec{r_1}\)\(=\begin{pmatrix} 3 \\ 4\end{pmatrix} = 3\begin{pmatrix}1 \\ 0 \end{pmatrix} + 4\begin{pmatrix}0 \\ 1\end{pmatrix} = 3\hat{i} + 4\hat{j}\), while the green vector \(\vec{r_2}\)\(=-2\hat{i}-\hat{j}\).
The definition of a vector does not depend on the position of the vector’s tail. The orange and purple vectors below are equivalent, no matter where they are placed in the plane. Each indicates a displacement of one unit to the right, and two units up, \(\langle 1, 2\rangle \hspace{1mm} \text{or} \begin{pmatrix} 1 \\ 2\end{pmatrix}\):
1.5.2 Vector Components
We can switch between notations using sine, cosine, and tangent. In particular, if we are given the length of a vector and the angle it makes with the horizontal, we can obtain the x- and y- components, and vice versa.
1.5.3 Negative of a Vector
Multiplying a vector by \(-1\) rotates the vector by \(180^{\circ}\). This is illustrated on the graph below:
Suppose vector \(\vec{a} = \begin{pmatrix} a_x \\ a_y \end{pmatrix}\) is multiplied by any constant \(c\). Then we define \(c\cdot\vec{a} = \begin{pmatrix} c\cdot a_x \\ c\cdot a_y \end{pmatrix}\). In particular, \(-\vec{a} = -1\cdot\vec{a} = \begin{pmatrix} -a_x \\ -a_y \end{pmatrix}\). This notation encodes the concept illustrated in the figure above.
1.5.4 Vector Addition
Now that we have a definition of vectors and some examples using the notation describing them, we can discuss operations that may be performed on two or more vectors. The first such operation is vector addition, illustrated in the diagram below:
Suppose we are given two vectors \(\vec{a} = \begin{pmatrix} a_x \\ a_y \end{pmatrix}\) and \(\vec{b} = \begin{pmatrix} b_x \\ b_y \end{pmatrix}\), then the sum \(\vec{a} + \vec{b} = \begin{pmatrix} a_x + b_x \\ a_y + b_y \end{pmatrix}\). Graphically, this means that we slide either \(\vec{a}\) or \(\vec{b}\) from the other vector’s tail to its tip. If we do this for both vectors, we produce a parallelogram as depicted above. For this reason, adding vectors is sometimes referred to as the “Parallelogram Rule” for adding vectors.
1.5.5 Vector Subtraction
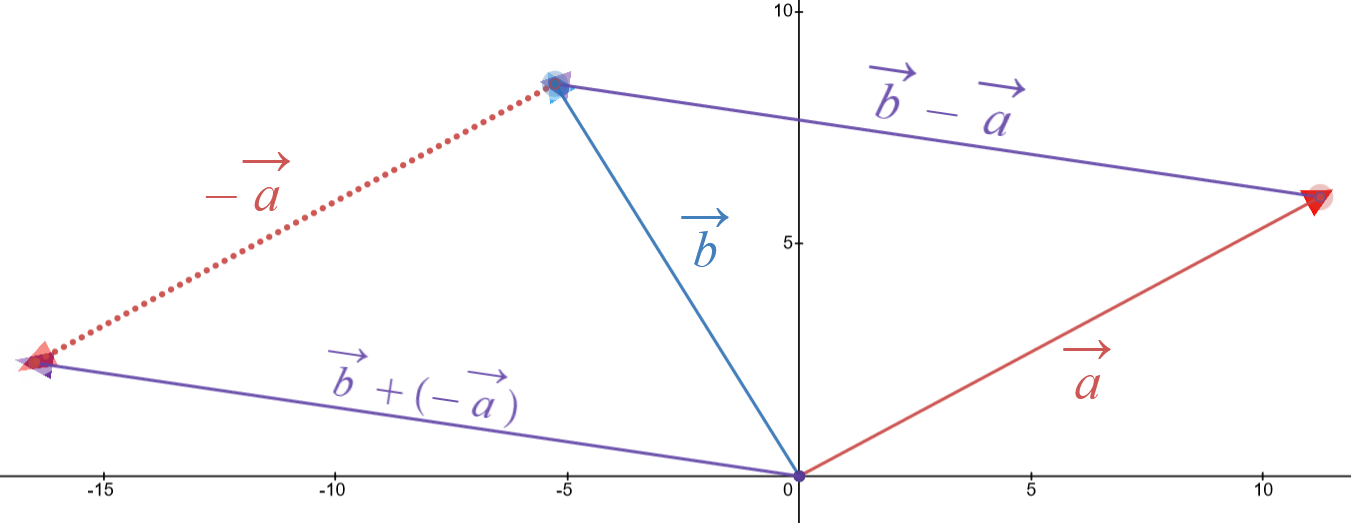
Vector subtraction is just as intuitive as vector addition. Suppose again that we are given two vectors \(\vec{a}\) and \(\vec{b}\). If we wish to compute \(\vec{b} - \vec{a}\) graphically, then we start from the tip of vector \(\vec{a}\) and draw the vector to the tip of vector \(\vec{b}\). This illustrated in the interactive plot below:
Suppose that \(\vec{a} = \begin{pmatrix} a_x \\ a_y \end{pmatrix}\) and \(\vec{b} = \begin{pmatrix} b_x \\ b_y \end{pmatrix}\). Then the vector \(\vec{b} - \vec{a} = \begin{pmatrix} b_x - a_x \\ b_y - a_y \end{pmatrix}\). Another way to express this difference is \(\vec{b} - \vec{a} = \vec{b} + (-\vec{a})\); that is, subtraction is simply addition with the second operand (in this case, vector \(\vec{a}\)) multiplied by \(-1\). This is illustrated in the figure below:
1.5.6 The Dot Product
A natural next question is whether multiplication can be defined for vectors. There are actually a few different and useful ways that multiplication can be defined between two vectors, but the one we will consider here is called the dot product.
The dot product is a different sort of multiplication than multiplication with real numbers. If one multiplies two real numbers together, then one gets a real number again. A vector is a bit different than a number; it is a two-dimensional object, a difference between two coordinates (each of which is two real numbers) instead of a single value. The dot product takes two vectors in, but spits a real number out; that is, it compresses the information contained between two vectors into a single number.
Suppose one has two vectors \(\vec{a} = \begin{pmatrix} a_x \\ a_y \end{pmatrix}\) and \(\vec{b} = \begin{pmatrix} b_x \\ b_y \end{pmatrix}\). We define the dot product to be \(\vec{a}\cdot\vec{b} = a_x b_x + a_y b_y\). In general, we have the following:
Definition 1.4 (Definition of the Dot Product) If given two vectors \(\vec{a} = \begin{pmatrix} a_1 \\ a_2 \\ \vdots \\ a_n \end{pmatrix}\) and \(\vec{b} = \begin{pmatrix} b_1 \\ b_2 \\ \vdots \\ b_n \end{pmatrix}\), then
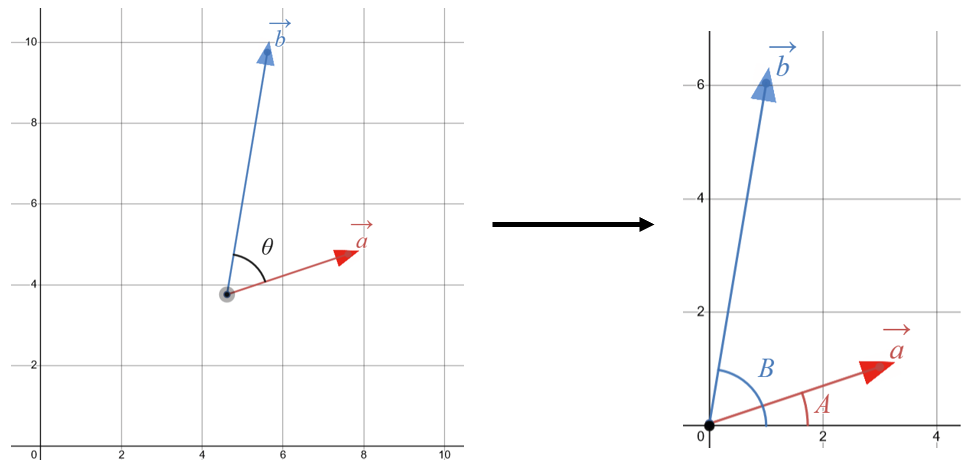
From this definition, we can derive another useful formula for the dot product. In fact, the formula we will provide is neater and is sometimes taken to be the definition of the dot product. Suppose I am given two vectors. We will creatively and affectionately refer to them as \(\vec{a}\) and \(\vec{b}\), as in the illustration below. Because it does not matter where the tails of these vectors are placed, we can move both to the origin:
We have defined the angle between vectors \(\vec{a}\) and \(\vec{b}\) to be \(\theta\). After placing the tails of the vectors onto the origin, we define two more angles. Angle \(A\) is the angle \(\vec{a}\) makes with the x-axis, while angle \(B\) is the angle \(\vec{b}\) makes with the x-axis. Notice that this means that \(\theta =\)\(B\)\(-\)\(A\).
We decompose each vector into its components as described above. That is, if we let \(a\) be the magnitude of vector \(\vec{a}\) and \(b\) be the magnitude of vector \(\vec{b}\), then we have:
\[ a_x = a \cos(A), \hspace{1.5mm} a_y = a \sin(A), \hspace{1.5mm} b_x = b \cos(B), \hspace{1.5mm} b_y = b\sin(B)\]
Recall our definition of the dot product (1.15). For our case, the dot product can be re-expressed as:
\[ \vec{a}\cdot\vec{b} = a_x b_x + a_y b_y \]\[ = a\cos(A)\cdot b\cos(B) + a \sin(A)\cdot b\sin(B)\]\[ = ab\cos(A)\cos(B) + ab\sin(A)\sin(B) \]\[ = ab\left(\cos(A)\cos(B) + \sin(A)\sin(B)\right) \]
The reader may recognize the quantity \(\cos(A)\cos(B) + \sin(A)\sin(B)\). It is (1.10)! Therefore, we have:
\[ ab\left(\cos(A)\cos(B) + \sin(A)\sin(B)\right) = ab\cos(B - A) = ab\cos(\theta)\]
That is, the dot product is the product of the length of two vectors times the cosine of the angle between them. This formula is true for vectors of any length. It is so important that we will provide it with a number:
The figure above illustrates the meaning of the dot product. We have a red vector \(\vec{a}\) and a blue vector \(\vec{b}\). If we rewrite the dot product as \(b\cdot(a\cos(\theta))\), then the dot product is the length of vector \(\vec{b}\) times the component of vector \(\vec{a}\) in the direction of vector \(\vec{b}\).
Where is the dot product positive? Where is it negative? For what angle is the dot product closest to zero?
One point to note is that the dot product of a vector with itself is the length of the vector squared. Let \(\vec{a}\) be some vector. The angle between \(\vec{a}\) and \(\vec{a}\) is obviously zero. Therefore, we have:
\[\begin{equation}
\vec{a}\cdot\vec{a} = a\cdot a \cos(0) = a^2
\tag{1.17}
\end{equation}\]
1.5.7 Law of Cosines
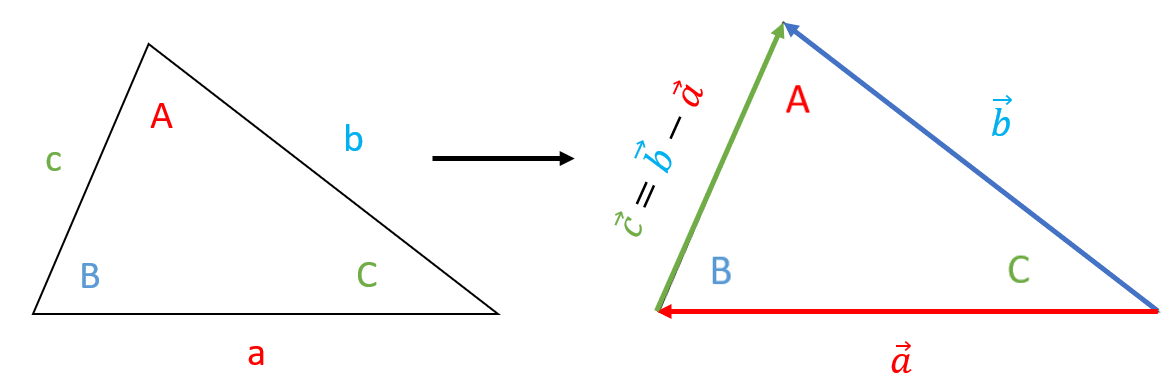
There is one last triangle rule we need before proceeding to exponents and logarithms. It is called the Law of Cosines, and the formulas describing the rule apply to any triangle. Suppose we superimpose some vectors onto the sides of some triangle, as illustrated below:
Now that we have this arrangement of vectors, we can apply the rules of vector addition, subtraction, and the dot product to the triangle on the right. In particular, recall that \(\vec{c}\cdot\vec{c} = c^2\), where the quantity on the right is the length of the vector squared. In this case, the length of the vector is simply the length of that side of the triangle. Therefore, we have the following:
Assuming we know the lengths of two sides of a triangle and the angle in between them, then we can find the length of the third side. This is the law of cosines:
Theorem 1.3 (Law of Cosines) Suppose we are given a triangle with side lengths \(a\), \(b\), and \(c\) and angles \(A\), \(B\), and \(C\) opposite those sides. Then the following formulas hold:
There is an important inequality that will arise frequently throughout this textbook. It is called the triangle inequality. The inequality is the following:
Theorem 1.4 (The Triangle Inequality) Let \(x\) and \(y\) be any real numbers. Then
\[|a + b| = \sqrt{(a + b)^2} \leq \sqrt{(|a| + |b|)^2} = |a| + |b| \]
Therefore, we have shown
\[|a + b| \leq |a| + |b|\]
But what does this mean? The foregoing equation can be generalized to vectors. Doing so will illustrate why this is called the triangle inequality. Recall from 1.5.5 that we can decompose the lengths of a triangle into three vectors \(\vec{a}\), \(\vec{b}\), and \(\vec{b} - \vec{a}\). We can use the dot product to obtain a vector-form of the triangle inequality:
\[(\vec{b} - \vec{a})\cdot (\vec{b} - \vec{a})\]
1.6 Exponents and Logarithms
1.6.1 Exponent Basics
Next, we will be provide an introduction to exponents, exponential functions, logarithms, and logarithmic functions. These concepts arise regularly in mathematics.
First, we recall that taking one number to the power of another number can be divided into two pieces, the base and the exponent:
When the exponent \({\color{green} b}\) is a positive integer, then we can interpret the operation as repeated multiplication, just as multiplication is repeated addition:
\[2^3 = 2\cdot 2 \cdot 2\]\[2^5 = 2\cdot 2 \cdot 2\cdot 2\cdot 2\]
In this case, 2 is the base, and 3 and 5 are exponents. This results in several intuitive rules regarding exponents:
Notice for this example that, as long as an exponent is treated as repeated multiplication, \(3^5\) can be decomposed into any set of integers whose sum is \(5\).
Note that the previous formula seems to suggest that \(a^0 = 1\) for any \(a\), since:
\[a^0 = a^{n-n} = \frac{a^n}{a^n} = \frac{\overbrace{a\cdot a\cdot \ldots \cdot a}^{\text{n times}}}{\underbrace{a\cdot a\cdot \ldots\cdot a}_{\text{n times}}} = \frac{a}{a}\cdot\frac{a}{a}\cdot\ldots\cdot\frac{a}{a} = 1\cdot 1\cdot\ldots\cdot 1 = 1\]
This property is so important that we will provide it with a number:
Formula (1.20) also gives us a natural way to define negative exponents. In particular, a negative exponent simply causes the base and its exponent to flip to the denominator:
We now have a sensible definition and nice set of rules for exponents when the exponent is an integer. What do we do if the exponent is a rational number? The reader is likely already familiar with the concept of the square root. By definition, the square root of a number is simply some number taken to the one-half power:
\[\sqrt{a} = a^{\frac{1}{2}}\]
Using formula (1.24), we can determine the value for square roots of perfect squares:
\[ \sqrt{9} = \sqrt{3^2} = (3^2)^{\frac{1}{2}} = 3^{2\cdot\frac{1}{2}} = 3 \]
That is, 3 is the number that, when multiplied by itself, returns 9.
Everything is well and good. But now suppose we are asked to compute the square root of 2 (\(\sqrt{2}\)). We are looking for a number that, when multiplied by itself, returns 2. Such a number is certainly not an integer. As is shown in the appendix, it isn’t rational, either. It probably isn’t immediately obvious how we should begin computing the value of square roots. Calculators and computers will do it easily, but how could we do so without one?
We will provide efficient methods using Calculus (see 4.4), but we give a very simple algorithm here for computing square roots, illustrated and described below.
Example 1.13 (Square Root of 2) I will finish this example later
Love,
Chandler
This procedure can be repeated for cube roots (\(\sqrt[3]{a} = a^{\frac{1}{3}}\)), quartic roots (\(\sqrt[4]{a} = a^{\frac{1}{4}}\)), or any integer root (\(\sqrt[n]{a} = a^{\frac{1}{n}}\)).
With this basic understanding of fractional exponents, we can define any rational exponent, where \(p\) and \(q\) are integers. In particular, if \(a\) is our base and we are it to the \(\frac{p}{q}\) power, then we are multiplying \(a\) by itself \(p\) times and taking the \(q\text{th}\) root:
We could, in principle, put all sorts of things into an exponent! By the end of this book, we will have even placed complex numbers and matrices into the exponent. For now, we will get moderately wild and place irrational numbers in the exponent. Consider the value of, say, \(5^{\sqrt{2}}\).
Our original definition of an exponent was repeated multiplication. Our definition was reasonable up to rational numbers, but what does it mean to multiply \(5\) by itself \(\sqrt{2}\) times? The notion of repeated multiplication is simply not reasonable for irrational exponents. Therefore, we will have to devise a new scheme to handle this class of numbers. When making generalizations, it is imperative that a mathematician consider the basic cases which resulted in a need for a more general case.
For this example, we will regard \(5^{\sqrt{2}}\) as some symbol which stands for a sequence of numbers which converges in the limit to a value. Note that word ‘limit’ has appeared again! This concept is the basis of Chapter BLANK.
To explore what this means, we return to the algorithm described in 1.13. If we were to write out the value of our approximation of \(\sqrt{2}\) from each step, it would look like the following:
\[1, 1.4, 1.41, 1.414, 1.4142, 1.41421, \hspace{1mm} \ldots\]
Because these decimals terminate, they can be rewritten as rational numbers:
\[1, \frac{14}{10}, \frac{141}{100}, \frac{1414}{1000}, \frac{14142}{10000}, \frac{141421}{100000}, \hspace{1mm} \ldots\]
We do know how to compute a value when the exponent is rational. Therefore, if we were living before the age of calculators and computers and other computing machines and were serious masochists, we may have considered the following to arrive at \(5^{\sqrt{2}}\):
If you enter \(5^{\sqrt{2}}\) into your calculator and compare the value to each of the terms in the sequence above, you would see that the sequence does indeed approach the value of \(5^{\sqrt{2}}\). Furthermore, it can be shown that, using this definition of irrational exponents, the rules (1.19) - (1.25) are still satisfied. For the time being, this will be our loose definition of numbers involving irrational exponents.
1.6.2 Graphs of Exponential Functions
If \(a > 0\), we can also consider functions of the form \(f(x) = a^x\), where \(x\) is any real number. A plot of exponential functions is provided below:
There are several important facts which deserve special attention:
Regardless of the value of \(a\) (assuming that it’s greater than zero), every single plot intersects at the point \((0, 1)\). This is due to the fact that \(a^0 = 1\).
When \(0 < a < 1\), the function is strictly decreasing.
When \(a > 1\), the function is strictly increasing.
If a system can be modeled by a function \(f(x) = a^x\) where \(0 < a < 1\), the system is said to be experiencing exponential decay. Radioactive nuclei decay according to an exponential function.
If a system can be modeled by a function \(f(x) = a^x\) where \(a > 1\), the system is said to be experiencing exponential growth. Compound interest is an example of a system which experiences exponential growth.
1.6.3 Examples Involving Exponents
1.6.3.1 Compound Interest
When you place money into a bank account, it is likely that interest is added to the principal placed into the account. The principal is the initial amount of money placed into the account, while the interest is the money that is added to the account over time. We first consider an example, then explore this concept further:
Example 1.14 (Simple Interest Calculation) Suppose you place \(5000\) into a bank account with an annual interest rate of \(5\%\). How much money will be in your account by the end of the year?
The bank is going to add 5% of the principal into your account by the end of the year. Therefore, the bank will add \(0.05*\$5000 = \$250\). Hence, by the end of the year, your bank account will contain \(\$5250\).
Suppose now that you place \(\$5000\) into your bank account and leave it there for two years. After the first year, your account will (somewhat magically) contain \(\$5250\). Then, interest is applied again; however, now the interest isn’t being applied just to the principal, but to the principal plus the interest. That is, you will have \(\$5250\cdot(1 + 0.05) = \$5512.50\). Notice that, after the first compounding, you magically made \(\$250\) in interest. After the second compounding, you magically made \(\$5512.50 - \$5250 = \$262.50\). You made more money after the second compounding than you did after the first! This is because you are applying the interest rate to money you already earned as interest. The idea of applying interest on interest that was already added to the principal is referred to as compound interest. This is an important example of exponential growth described above. As the money in your account grows, the speed at which money is added to your account grows, too.
Thinking about compound interest resulted in the discovery of a special mathematical constant that appears almost everywhere in mathematics. Before making this discovery for ourselves, we must derive a formula for compound interest for any interest rate and the number of times our money is compounded per year.
Example 1.15 (Compound Interest Calculation 1) Suppose you place \(\$100\) in your bank account which is compounded quarterly at an annual interest rate of \(4\%\). How much money will be in your bank account by the end of the year?
To be compounded quarterly means that we are applying interest four times per year. There is one caveat, though; since we have an annual interest rate of \(4\%\) and we are compounding quarterly, we should only apply \(1\%\) interest each quarter so that it sums to \(4\%\). That is, \(\frac{4\%}{4} = \frac{0.04}{4} = 0.01\)
After the first quarter, there will be \(\$100\cdot(1 + \frac{0.04}{4}) = \$101\) in your account.
After the second quarter, there will be \(\$101\cdot(1 + \frac{0.04}{4}) = \$102.01\) in your account.
After the third quarter, there will be \(\$102.01\cdot(1 + \frac{0.04}{4}) \approx \$103.03\) in your account.
After the fourth quarter, there will be \(\$103.03\cdot(1 + \frac{0.04}{4}) \approx \$104.06\) in your account.
Therefore, by the end of the year, your bank account will have \(\$104.06\) inside, assuming an annual interest rate of \(4\%\) compounded quarterly.
We can simplify the analysis in the previous example. Notice that whenever we compound for one quarter, the result is used for the next quarter, as depicted below:
We can think of this as multiplying \(\left(1 + \frac{0.04}{4}\right)\) four times. Therefore, we can rewrite this as \(\$100\left(1+\frac{0.04}{4}\right)\left(1+\frac{0.04}{4}\right)\left(1+\frac{0.04}{4}\right)\left(1+\frac{0.04}{4}\right) = \$100\cdot\left( 1 + \frac{0.04}{4}\right)^4 \approx \$104.06\)
Notice that the denominator of the fraction in the parentheses and the exponent are the same. This is true in general. So far, then, we have the following formula:
\[ A = P\cdot\left(1 + \frac{r}{n}\right)^n \]
where
\(P\) is the principal (the initial amount of money invested) \(r\) is the annual interest rate, divided by \(100\). \(n\) is the number of times interest is applied per year.
There is one more piece that we need to add to this formula to put it into its final form. Suppose we wanted to invest our money in a bank for many years instead of only one year. In particular, suppose we returned to example 1.15, but we invested our money for two years instead of one year. As before, at the end of one year, you would have \(A = \$100\cdot\left(1 + \frac{0.04}{4}\right)^4 \approx \$104.06\). Now we perform the exact same operation to determine how much money you will have at the end of the second year. However, we now use \(\$104.06\) as our principal: \(A = \$104.06\left(1 + \frac{0.04}{4}\right)^4 \approx \$108.29\). Instead of multiplying \(\left(1 + \frac{0.04}{4}\right)^4\) for both years, we can simply multiply by \(\left(1 + \frac{0.04}{4}\right)^8\):
This leads to the general formula for compound interest:
Theorem 1.5 (Compound Interest) Suppose you initially invest \(P\) dollars into an account earning interest. The amount in your account after \(t\) years is given by:
\[ A = P\cdot\left(1 + \frac{r}{n}\right)^{nt} \]
Where
\(A\) is the amount of money in your account after \(t\) years \(P\) is the principal amount invested \(r\) is the annual interest rate divided by \(100\) \(n\) is the number of times interest is applied per year \(t\) is the number of years the principal remains in the account earning interest.
In this formula, \(n\) can be made to be any value. For instance, if we wanted to know how much money would be in our account if interest were added on a daily basis, we would use \(n = 365\), since there are \(365\) days in a year.
We will provide some examples, then you will have the opportunity to test your understanding in the exercises.
Example 1.16 (Compound Interest Calculation 2) Suppose you place \(\$2000\) into a bank account earning \(2.5\%\) interest compounded daily for \(5\) years. How much money will be in your account after those five years?
For this example, we have the following:
\(P = \$2000\) \(r = 0.025\) \(t = 5 \hspace{1mm}\text{years}\) \(n = 365 \hspace{1mm}\text{days}\) (since we are compounding daily)
\[A = P\cdot\left(1 + \frac{r}{n} \right)^{nt} = 2000\cdot\left(1 + \frac{0.025}{365} \right)^{365\cdot 5} \approx \$ 2266.29\]
In other words, you earned \(\$266.29\) for doing absolutely nothing!
1.6.4 The Number e
Now that we have a nice formula to compute compound interest, we can begin to ask some silly questions which will lead to an important result. This is fairly common in mathematics: seemingly stupid questions often reveal interesting answers.
Example 1.17 (Origin of e) Sobs Oh woe to you! You have only \(\$1\) to place into your bank account! Upon placing your last dollar in the account, you are informed that this bank account is peculiar: it has an annual interest rate of \(100\%\). How much money will be in your bank account after one year if interest is compounded
Annually?
Weekly?
Daily?
Hourly?
Every second?
In each case, we can apply formula 1.5 with different values of \(n\) for each case to compute the amount of money you will have after \(t = 1 \hspace{1mm}\text{year}\). Because the bank offers a generous \(100\%\) interest rate, \(r = 1\). Finally, because you spent the rest of your money on Fortnite skins, \(P = \$1\):
For the annual case, \(n = 1\): \[A = \$1\cdot\left(1 + \frac{1}{1} \right)^1 = \$2\]
For the weekly case, \(n = 52\): \[A = \$1\cdot\left(1 + \frac{1}{52} \right)^{52} = \$2.6926 \]
For the daily case, \(n = 365\): \[A = \$1\cdot\left(1 + \frac{1}{365} \right)^{365} = \$2.7146 \]
For the secondly case, \(n = 8760\hspace{1mm}\text{hours}\cdot\frac{3600\hspace{1mm}\text{seconds}}{1\hspace{1mm}\text{hour}} = 31536000\hspace{1mm}\text{seconds}\): \[A = \$1\cdot\left(1 + \frac{1}{31536000} \right)^{31536000} \approx \$2.718282 \]
Notice in the previous example that, as time is chopped up ever more finely, the growth in your money is increasing. That is, you earn more money in interest if interest is applied every second of a year than if it is only applied once that year.
There is another peculiar fact to notice: as we chop up time more finely, the amount of growth decreases. For example, the difference in the amount you make between interest being applied annually and interest being applied weekly is \(\$0.6926\). On the other hand, the difference in interest earned between the hourly and the secondly case is \(\$0.000182\).
Now we ask the question: what if we let time become as small as possible? Is it possible to apply interest every millisecond? Every nanosecond? Continuously? Given the previous result, it seems that if we let \(n\) approach infinity (so we’re compounding more frequently), the quantity approaches some number. It turns out the answer is yes: the number that this quantity approaches is called \(e\), called Euler’s Number in honor of the Swiss mathematician Leonhard Euler. This is yet another limiting process that we will describe using the notation introduced in the next chapter:
In words, this definition states that the quantity \(\left(1 + \frac{1}{n}\right)^n\) converges to some number as we let \(n\) become ever larger. This is very similar to the calculation of the circumference described by Archimedes. As we let \(n\) become bigger and bigger, we are multiplying more and more terms (because of the \(n\) in the exponent), so one might conclude that \(\left(1 + \frac{1}{n}\right)^n\) is going to become larger and larger as \(n\) does. On the other hand, as \(n\) becomes larger and larger, \(\frac{1}{n}\) becomes smaller and smaller, so the number we’re multiplying repeatedly is decreasing. This is just like the circumference example. For the circumference, we have more and more segments approximating the area, but they become shorter and shorter. In that case, the length of the segments converges to \(2\pi\). This balance achieved by a limiting process is the heart of Calculus, and is the third example of such a process we have seen just in the introductory chapter of this text.
It is impossible to overstate the importance of this constant: besides \(\pi\), it seems to be the most important number in the universe. It appears in every branch of science and mathematics. Part of the reason for its importance is it special relationship to the logarithm, described next.
1.6.5 The Logarithm
1.6.5.1 Definition
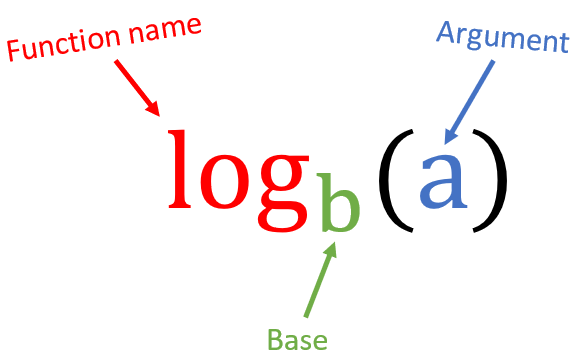
In beginning our discussion of exponents, we roughly defined exponents as repeated multiplication. We also define an operation whose definition is (also roughly) repeated division. It is called the logarithm.
The Function name denotes the operation we are performing. In this case, it is a logarithm. The base is the number we will be dividing the argument by. What the logarithm returns is the number of times the argument must be divided by the base to return \(1\). A few examples will help illustrate:
Example 1.18
Compute \(\log_3(81)\).
There are two ways to think about this. We could simply start dividing \(81\) by \(3\) and continue until we reach \(1\):
\[\underbrace{\frac{81}{3} = 27}_1, \hspace{2mm} \underbrace{\frac{27}{3} = 9}_2, \hspace{2mm} \underbrace{\frac{9}{3} = 3}_3, \hspace{2mm} \underbrace{\frac{3}{3} = 1}_4\]
Therefore, \(\log_3(81) = 4\). Alternatively, we could notice that \(3^4 = 81\). Therefore, we must divide four \(3\text{'s}\) to reach one. Therefore,
\[\log_3(81) = \log_3(3^4) = 4\]
1.6.5.2 Rules
Now that we have defined what a logarithm is, there are some important rules for logarithms which follow from the exponent rules, (1.19) - (1.25):
\[\begin{equation}
\log_a(a^x) = x \hspace{2mm} \text{and} \hspace{2mm} a^{\log_a(x)} = x
\tag{1.26}
\end{equation}\]
The first rule follows from the definitions of exponents and logarithms; in particular, they are inverse operations. The rest will be proven using the rules for exponents.
Proof (Proof of 2.21). First, recall that exponential functions are injective (one-to-one) functions; therefore, if \(a^x = a^y\), then \(x = y\).
\[a^{\log_a{xy}} = xy = a^{\log_a{x}}a^{\log_a{y}} = a^{\log_a{x} + \log_a{y}}\]
Therefore, because exponential functions are one-to-one, it must be that \(\log_a{xy} = \log_a{x} + \log_a{y}\).
The following is called the Change of Base Formula. It will be used repeatedly when considering derivatives and integrals of logarithm functions.
Proof (Proof of 2.22). Consider the quantity \(c^{\log_c(b)\log_b(a)}\). Notice that this can be rewritten as \((c^{\log_c(b)})^{\log_b(a)}\). Therefore, we have the following string of equalities:
Finally, we will prove a rule that will also be used repeatedly in this text. It is essentially a result of the third rule described above.
Proof (Proof of 2.23). We want to compute the value of \(\log_b(a^x)\). By the rule above, we can change the base of the logarithm from \(b\) to \(a\):
\[ \log_b(a^x) = \frac{\log_a(a^x)}{\log_a(b)} = \frac{x}{\log_a(b)}\]
We now must use the change of base formula to change the base \(a\) back to \(b\):
The natural logarithm is like very other logarithm, but its base is Euler’s number, 1.5. It is denoted by \(\ln(x)\). As we will see in Chapter 3, this logarithm has special derivative properties, thus making it the ‘natural logarithm’.
1.6.5.4 Graphs of Logarithmic Functions
Logarithm functions are the inverse of exponential functions. Below is an illustration depicting logarithm functions for different values of the base.
Note the similarities between the rules of logarithm functions and exponential functions. In particular:
Regardless of the value of \(a\) (assuming that it’s greater than zero), every single plot intersects at the point \((1, 0)\) (For exponential functions, recall that this point is \((0, 1)\)).
When \(0 < a < 1\), the function is strictly decreasing.
When \(a > 1\), the function is strictly increasing.
1.7 Function Transformations
In this last section, we will be covering the topic of function transformations. Knowing how we can move functions about in space will be useful for the entire text, so it is vitally important to play with the graphic below to get a sense of what transformations are and how they work:
We will first show you the general formula for function transformations, then take each piece one at a time and analyze it. Let \(f(x)\) be some function in which we’re interested. Then the following function \(g(x)\) is a sequence of transformations of the function \(f(x)\):
Vertical means up/down. Translations are movements. Therefore, a vertical translation is a function’s movement up or down. Vertical translations are determined in the formula above by the letter \({\color{orange} d}\). Therefore, if we were interested only in a vertical translation, our function would look like this:
\[g(x) = f(x) + {\color{orange} d}\]
If \({\color{orange} d} > 0\), then we are shifting the function up \(\uparrow\).
If \({\color{orange} d} < 0\), then we are shifting the function down \(\downarrow\).
If \({\color{orange} d} = 0\), then we are not vertically shifting the function. If \({\color{orange} d} = 0\), we don’t include \(+ {\color{orange} d}\) in the formula.
1.7.2 Horizontal Translations
Horizontal means left/right. Translations are movements. Therefore, a horizontal translation is a function’s movement left or right. Horizontal translations are determined in the formula above by the letter \({\color{green} c}\). Therefore, if we were interested only in a horizontal translation, our function would look like this:
\[g(x) = f(x + {\color{green} c})\]
The rules for horizontal translations are peculiar to everyone when they’re first learned. Notice that as the dial for horizontal shifts is moved left, the function moves right. As the horizontal shift dial is moved right, the function moves left. Therefore, we have the following rules:
If \({\color{green} c} > 0\), then we are shifting the function left \(\leftarrow\).
If \({\color{green} c} < 0\), then we are shifting the function right \(\rightarrow\).
If \({\color{green} c} = 0\), then we are not horizontally shifting the function. If \({\color{green} c} = 0\), we don’t include \(+ {\color{green} c}\) in the formula.
1.7.3 Vertical Compression/Stretching
Vertical means up and down. Compression means to squish. Stretch means to stretch. Therefore, vertical compressions/stretches squish/stretch the function in the up or down direction. Vertical compressions/stretches are determined by \({\color{red} a}\) in the formula above. If we were interested only in vertical stretches/compressions, our function would look like this:
\[g(x) = {\color{red} a}f(x)\]
The rules for stretches/compressions is slightly more complicated than for translations. We have the following:
If \({\color{red} a} < -1\), the function is reflected across the \(x-\)axis and stretched.
If \(-1 < {\color{red} a} < 0\), the function is reflected across the \(x-\)axis and compressed.
If \({\color{red} a} = 0\), the whole function is mapped to the straight line \(y = 0\).
If \(0 < {\color{red} a} < 1\), the function remains upright and is compressed.
If \(1 < {\color{red} a}\), the function remains upright and is stretched.
1.7.4 Horizontal Compression/Stretching
Horizontal means left and right. Compression means to squish. Stretch means to stretch. Therefore, horizontal compressions/stretches squish/stretch the function in the left or right direction. Horizontal compressions/stretches are determined by \({\color{blue} b}\) in the formula above. If we were interested only in horizontal stretches/compressions, our function would look like this:
\[g(x) = f({\color{blue} b}x)\]
The rules for horizontal stretches and compressions is similar to the rules for vertical stretches and compressions. We have the following:
If \({\color{blue} b} < -1\), the function is reflected across the \(x-\)axis and stretched.
If \(-1 < {\color{blue} b} < 0\), the function is reflected across the \(x-\)axis and compressed.
If \({\color{blue} b} = 0\), the whole function is mapped to the straight line \(x = 0\).
If \(0 < {\color{blue} b} < 1\), the function remains upright and is compressed.
If \(1 < {\color{blue} b}\), the function remains upright and is stretched.